03:00
Simple Linear Regression
Aug 31, 2022

Data science life cycle from R for Data Science with modifications from The Art of Statistics: How to Learn from Data.
Movie ratings
- Data behind the FiveThirtyEight story Be Suspicious Of Online Movie Ratings, Especially Fandango’s
- In the fivethirtyeight package:
fandango - Contains every film that has at least 30 fan reviews on Fandango, an IMDb score, Rotten Tomatoes critic and user ratings, and Metacritic critic and user scores




Movie ratings data
The data set contains the “Tomatometer” score (critics) and audience score (audience) for 146 movies rated on rottentomatoes.com.
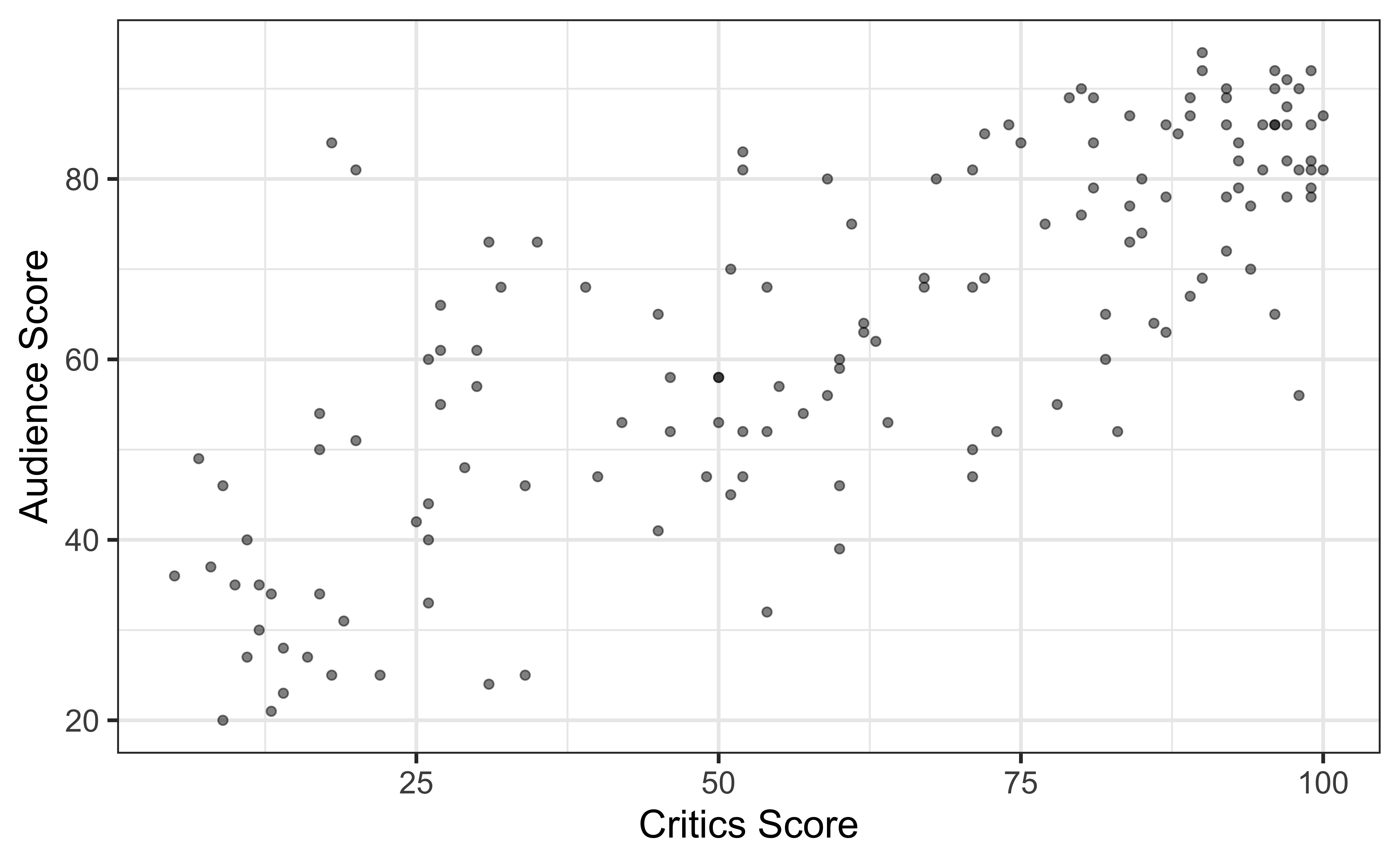
Movie ratings data
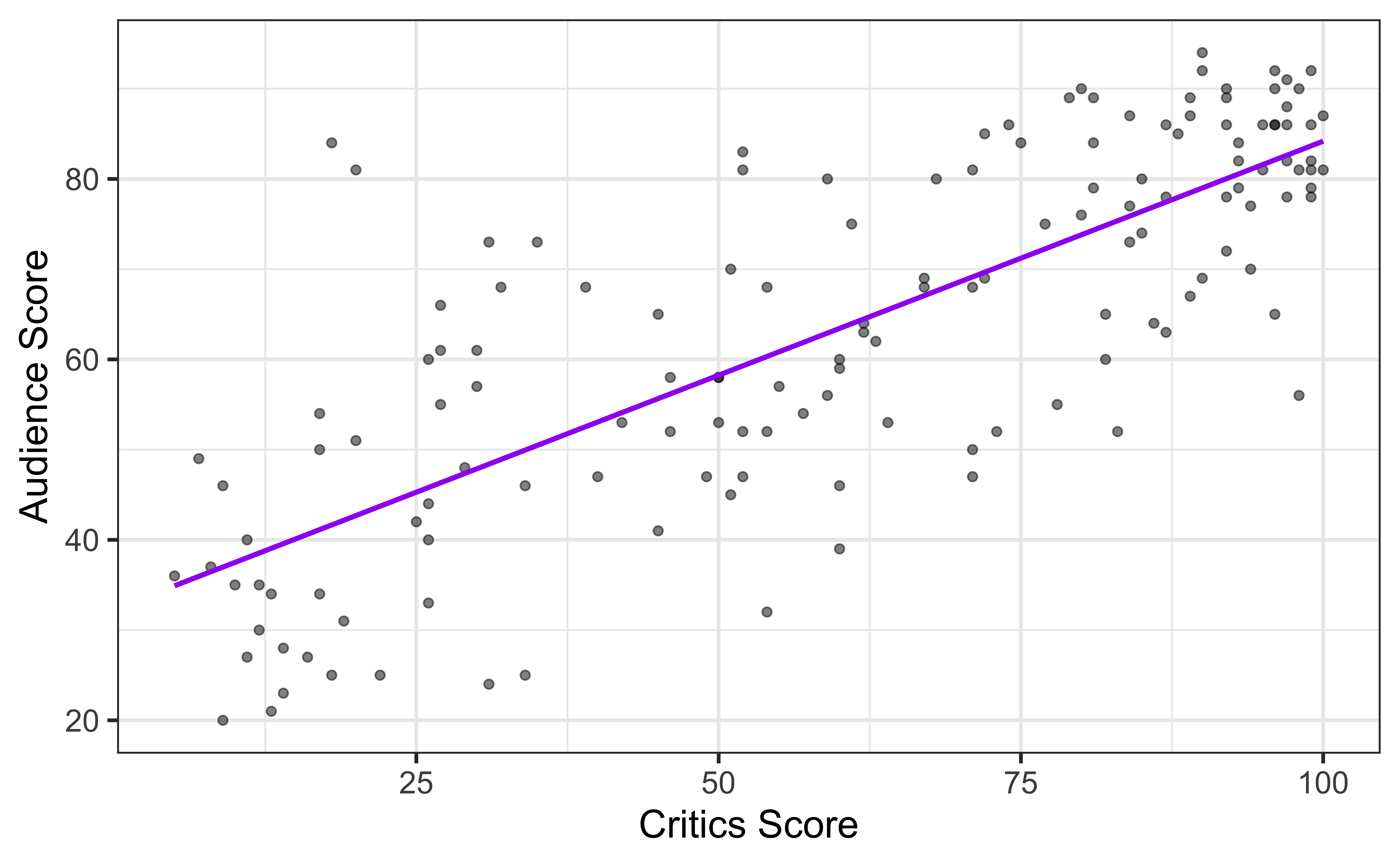
Goal: Fit a line to describe the relationship between the critics score and audience score.
Terminology
Response, Y: variable describing the outcome of interest
Predictor, X: variable we use to help understand the variability in the response
Regression model
\[\begin{aligned} Y &= \color{purple}{\textbf{Model}} + \text{Error} \\[8pt]
&= \color{purple}{\mathbf{f(X)}} + \epsilon \\[8pt]
&= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \epsilon \end{aligned}\]
\(\mu_{Y|X}\) is the mean value of \(Y\) given a particular value of \(X\).
Regression model
\[ \begin{aligned} Y &= \color{purple}{\textbf{Model}} + \color{blue}{\textbf{Error}} \\[5pt] &= \color{purple}{\mathbf{f(X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[5pt] &= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \color{blue}{\boldsymbol{\epsilon}} \\[5pt] \end{aligned} \]
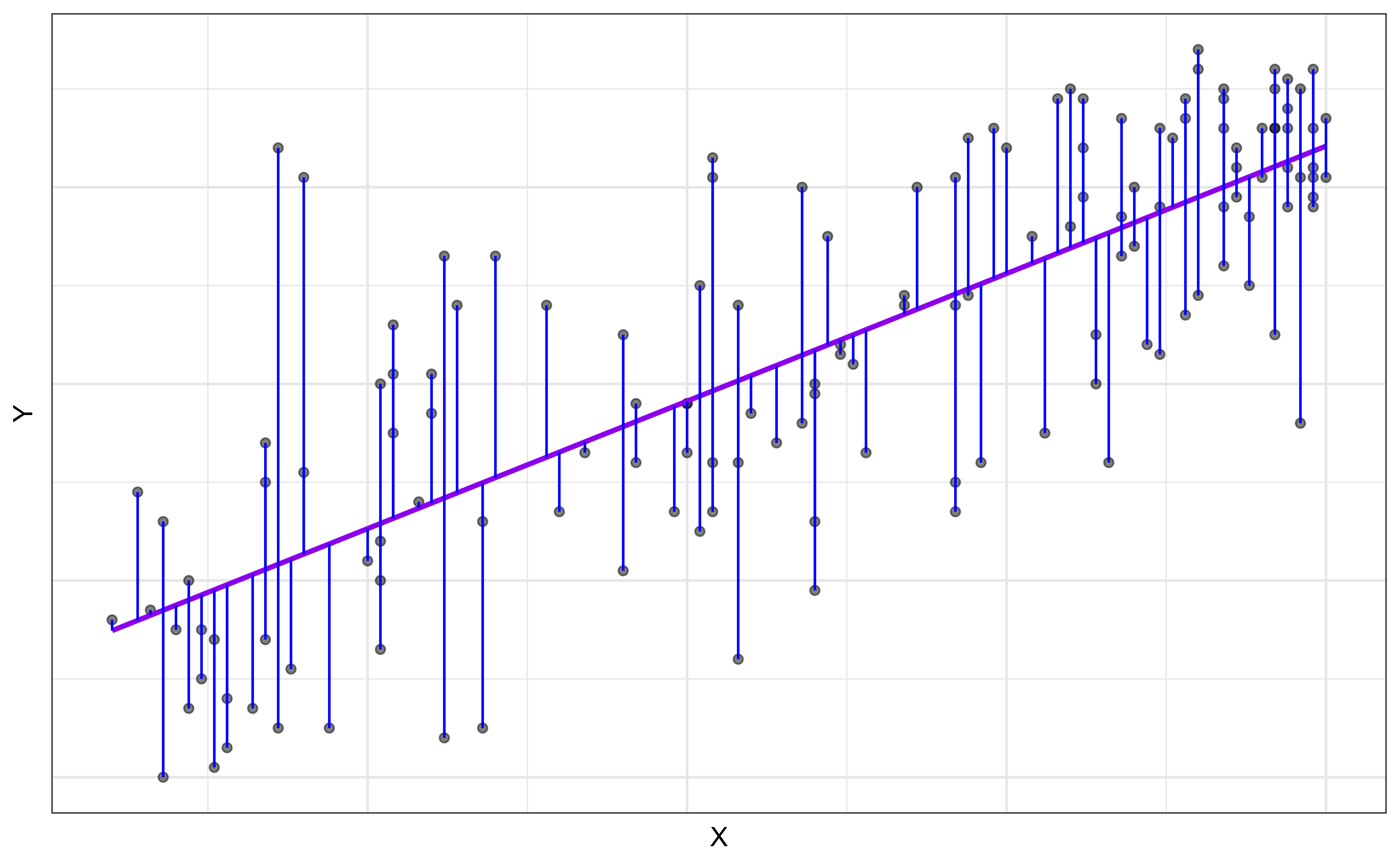
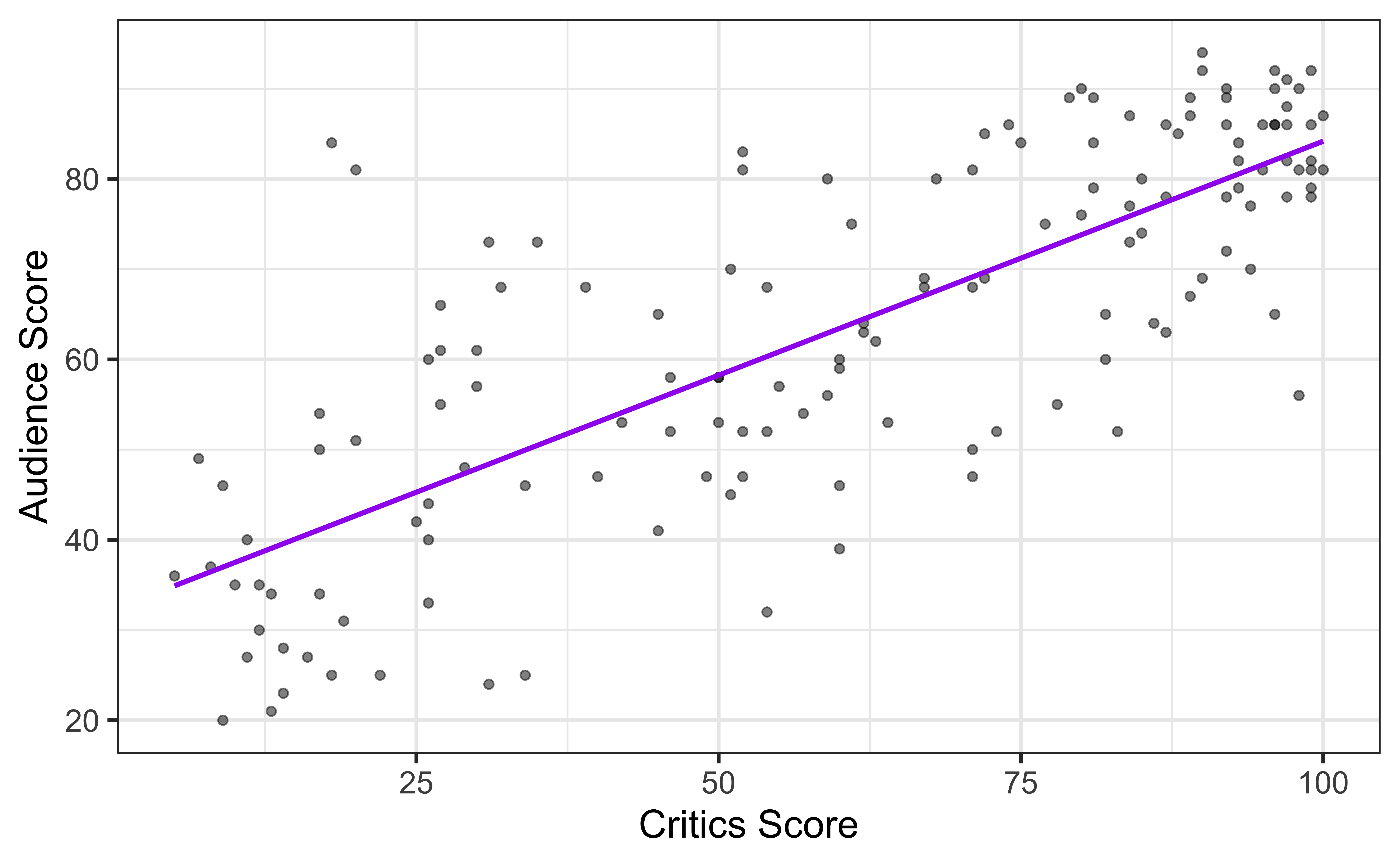
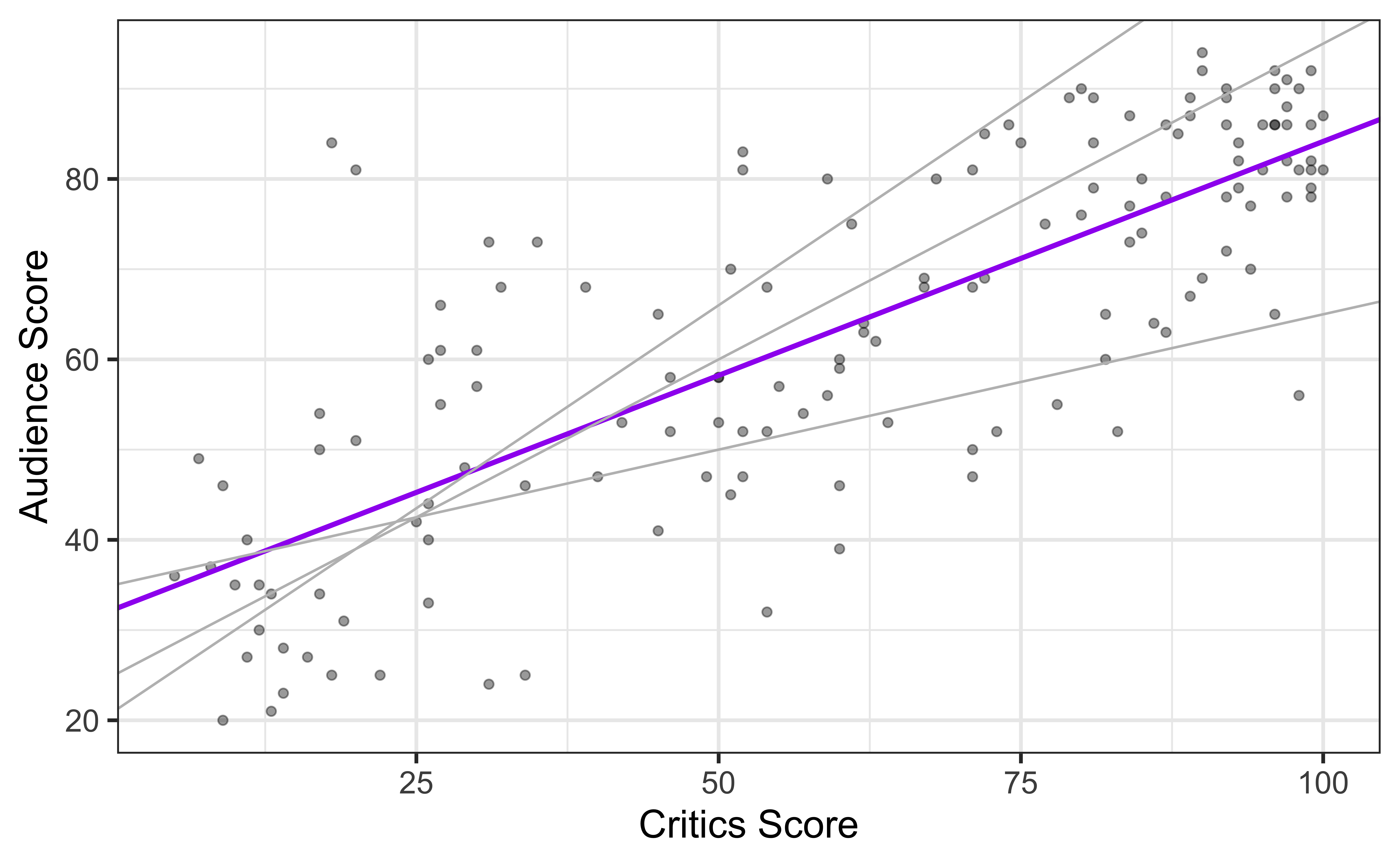
Choosing values for \(\hat{\beta}_1\) and \(\hat{\beta}_0\)
Residuals
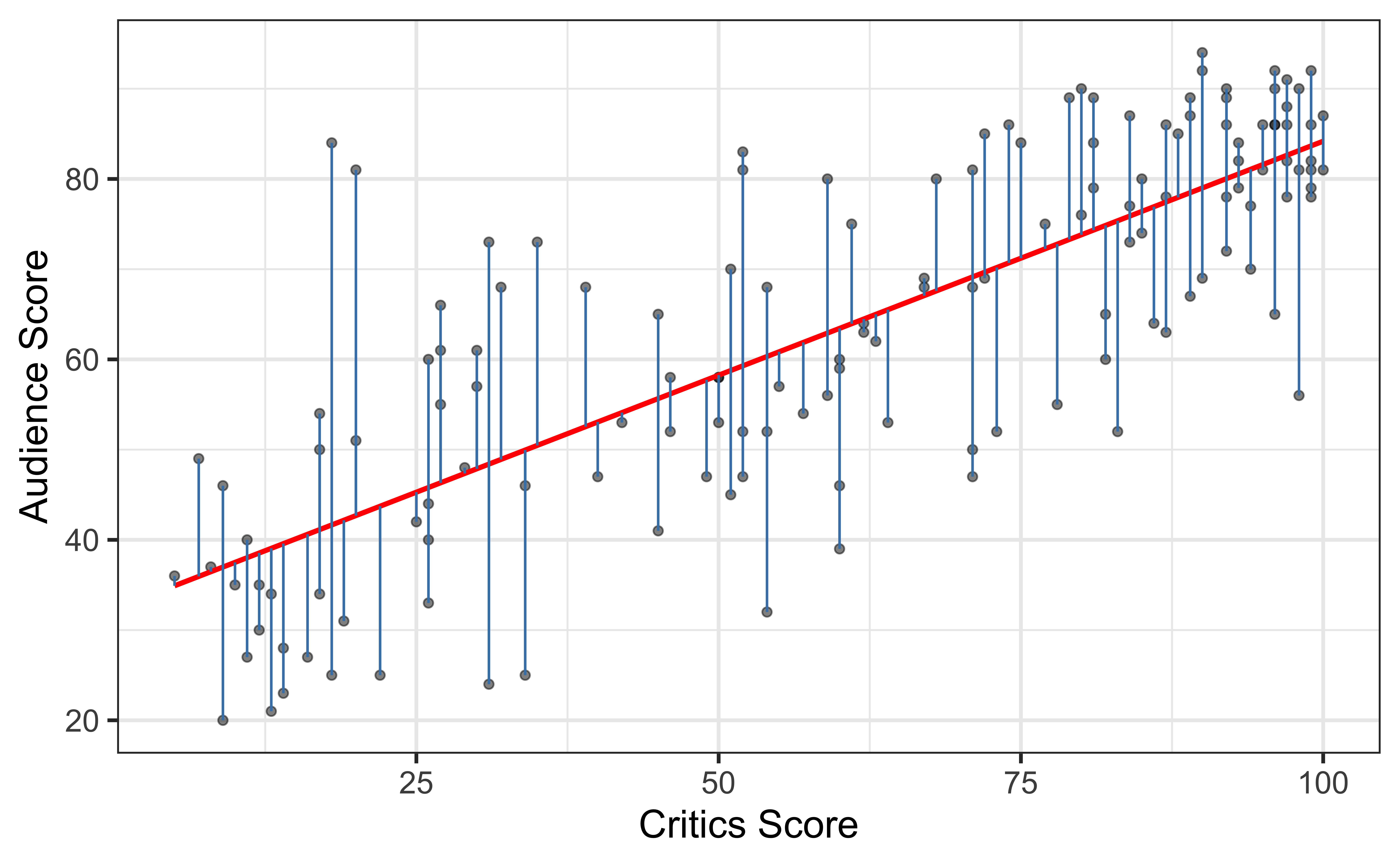
\[\text{residual} = \text{observed} - \text{predicted} = y - \hat{y}\]
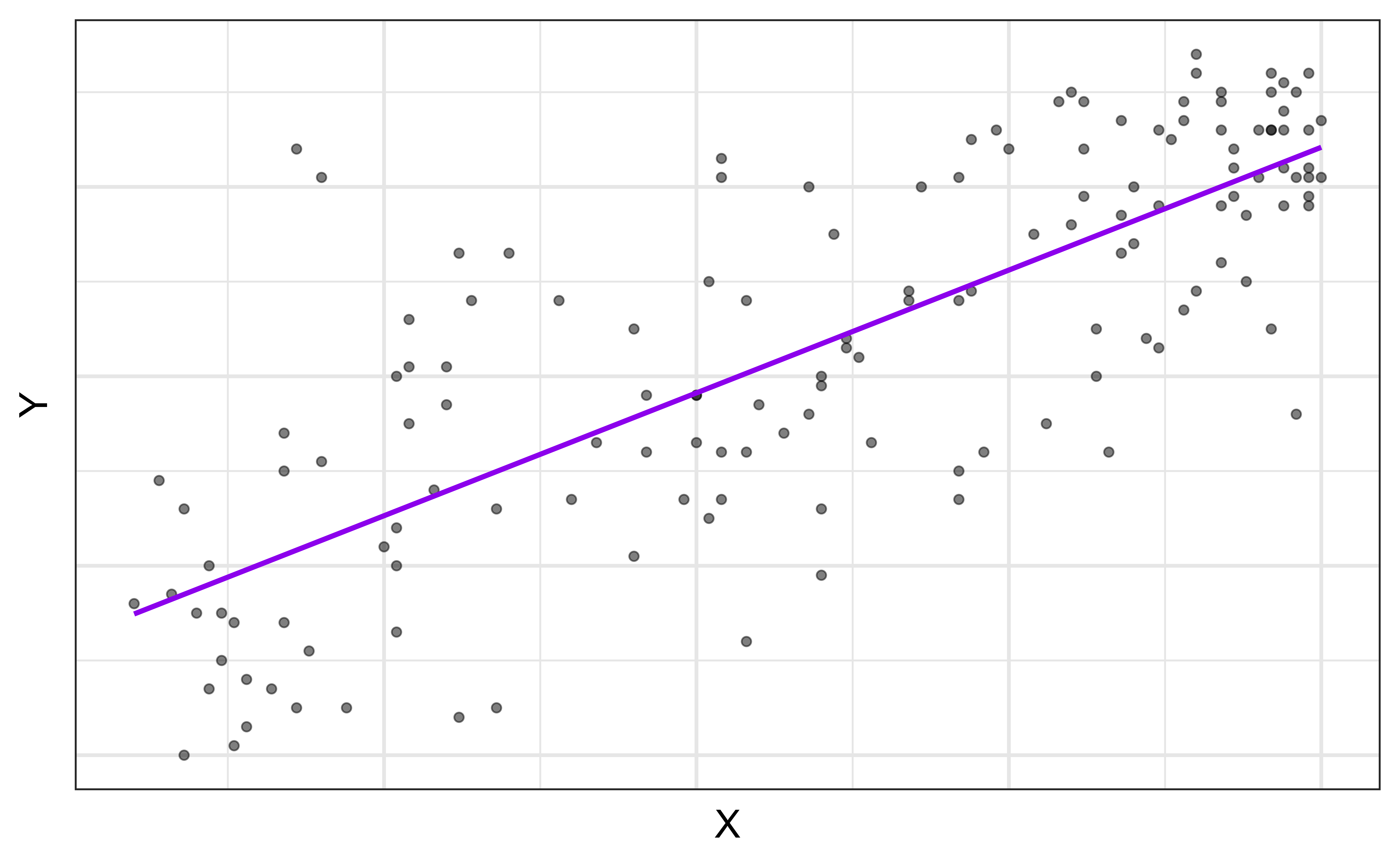
⚠️ Extrapolation
Using the model to predict for values outside the range of the original data is extrapolation.
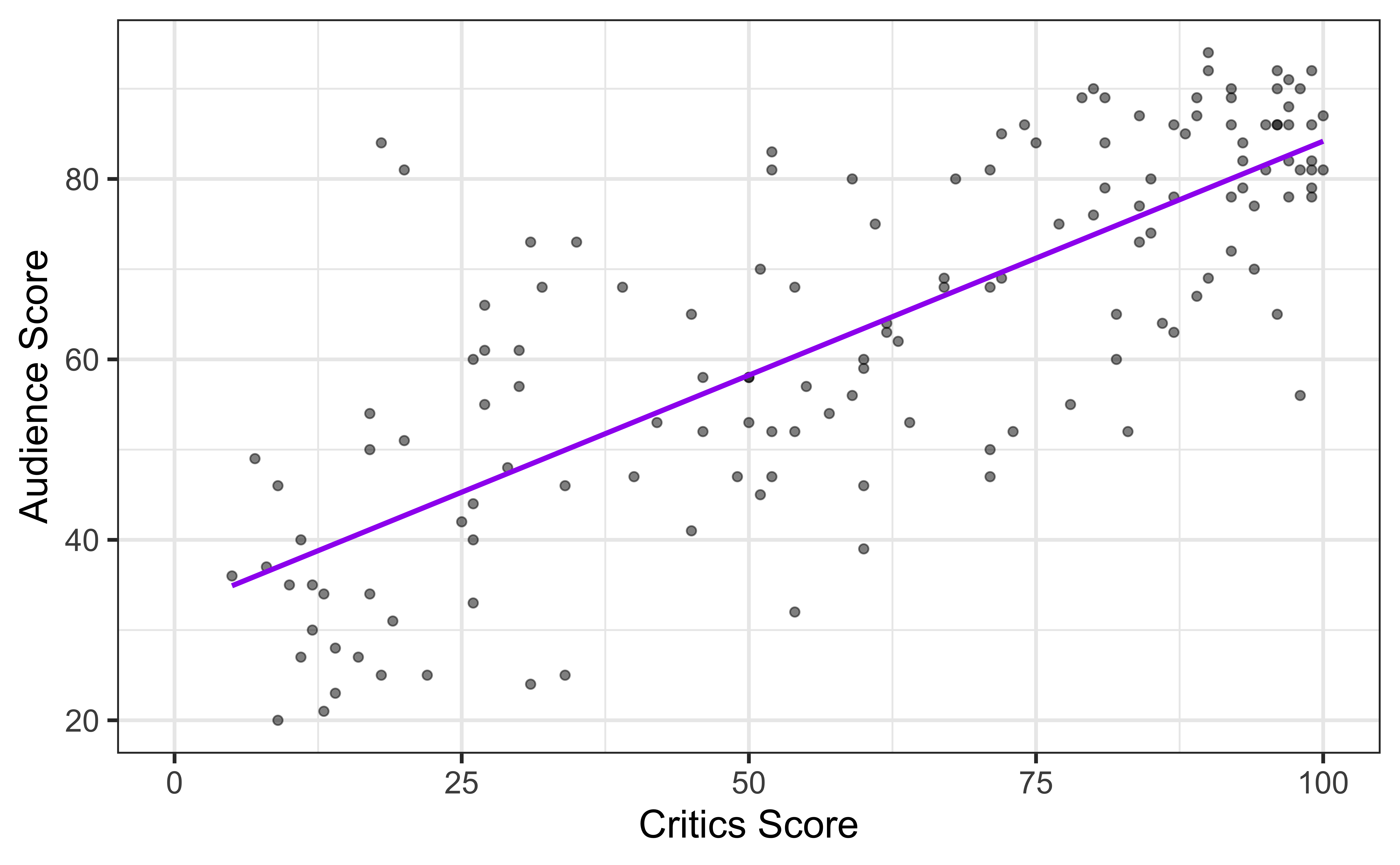
Suppose that a movie has a critics score of 0. According to this model, what is the movie’s predicted audience score?
Next class
We will talk about fitting linear models in R with tidymodels.
Reserve STA 210 Docker Container before Monday’s lecture
Complete the STA 210 Student Survey (will ask for a GitHub username) by Friday at 11:59pm