# load packages
library(tidyverse) # for data wrangling and visualization
library(tidymodels) # for modeling
library(usdata) # for the county_2019 dataset
library(openintro) # for Duke Forest dataset
library(scales) # for pretty axis labels
library(glue) # for constructing character strings
library(knitr) # for neatly formatted tables
library(kableExtra) # also for neatly formatted tablesf
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 16))SLR: Simulation-based inference
Bootstrap confidence intervals for the slope
Sep 12, 2022
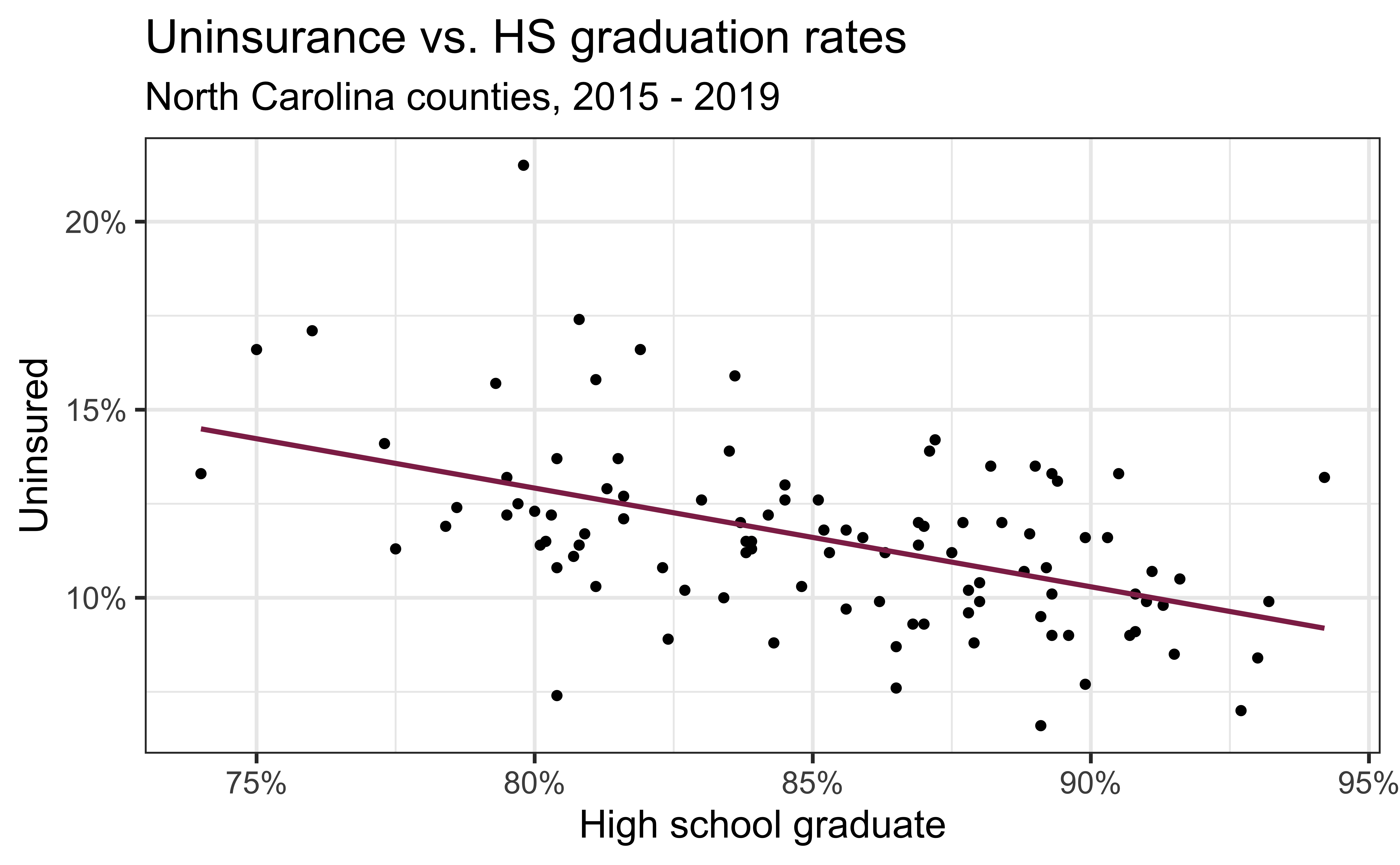
Uninsurance vs. HS graduation rates
Code
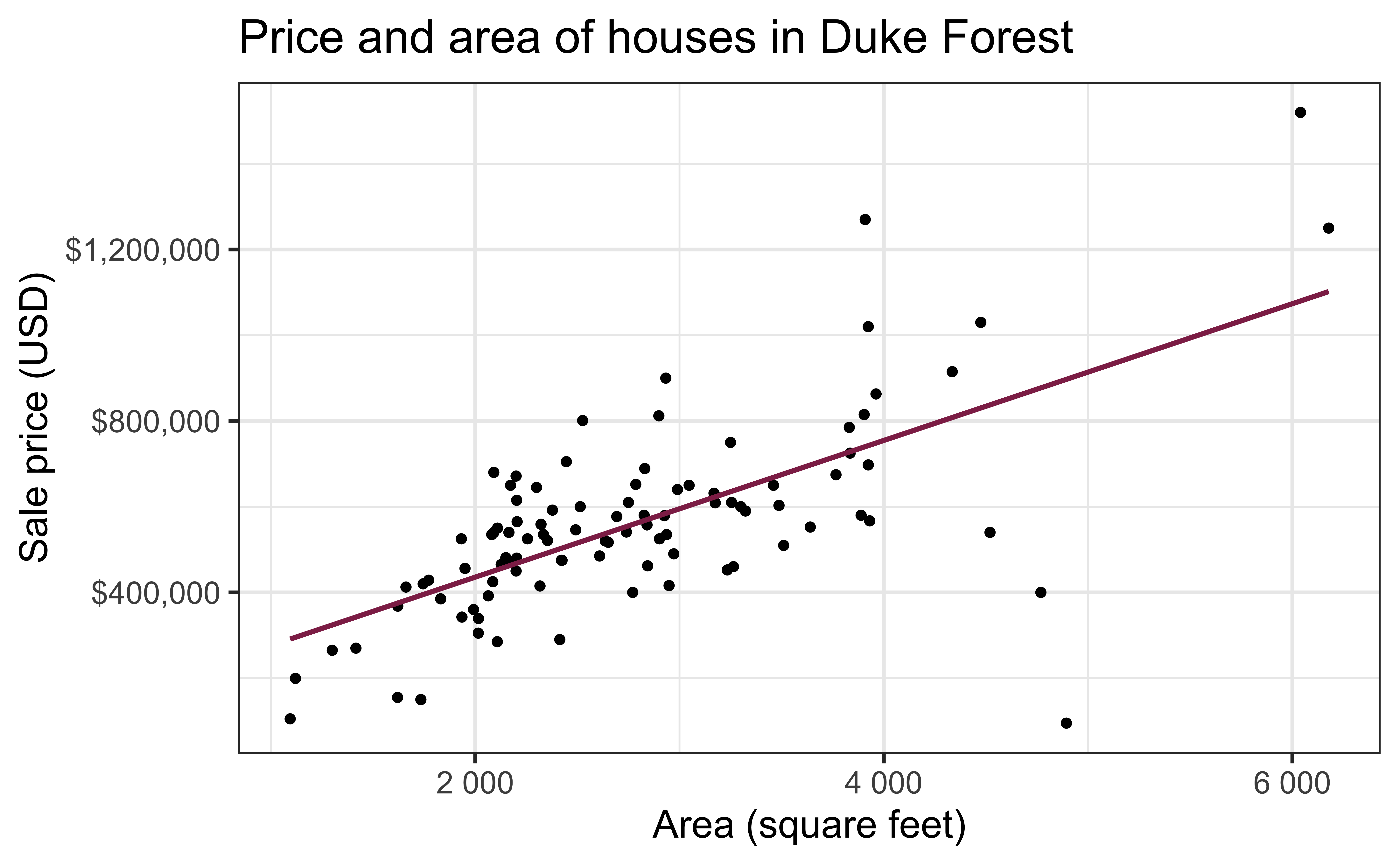
ggplot(county_2019_nc, aes(x = hs_grad, y = uninsured)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "#8F2D56") +
scale_x_continuous(labels = label_percent(scale = 1, accuracy = 1)) +
scale_y_continuous(labels = label_percent(scale = 1, accuracy = 1)) +
labs(
x = "High school graduate", y = "Uninsured",
title = "Uninsurance vs. HS graduation rates",
subtitle = "North Carolina counties, 2015 - 2019"
)
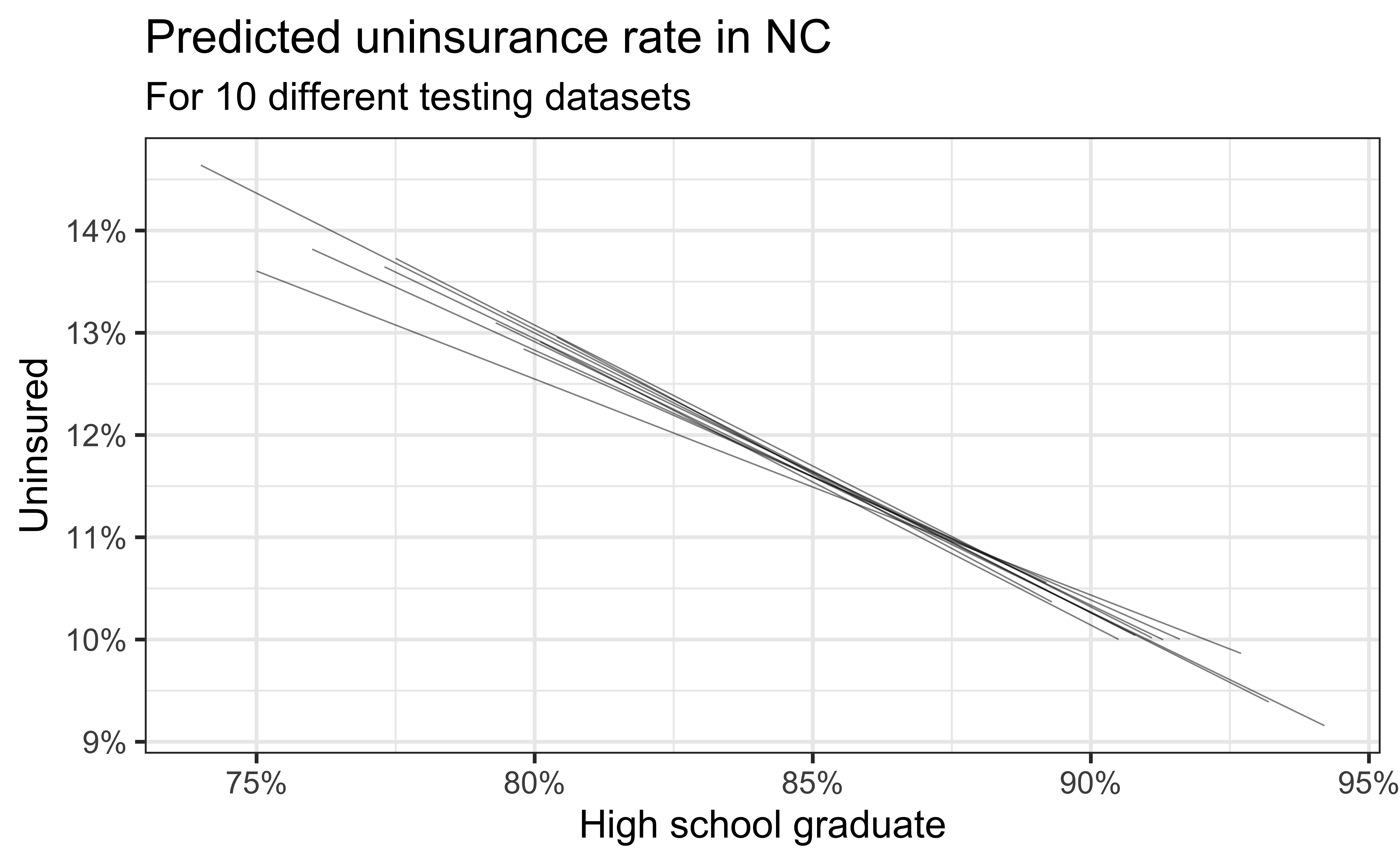
Simulation: data splitting
- Take a random sample of 10% of the data and set aside (testing data)
- Fit a model on the remaining 90% of the data (training data)
- Use the coefficients from this model to make predictions for the testing data
- Repeat 10 times
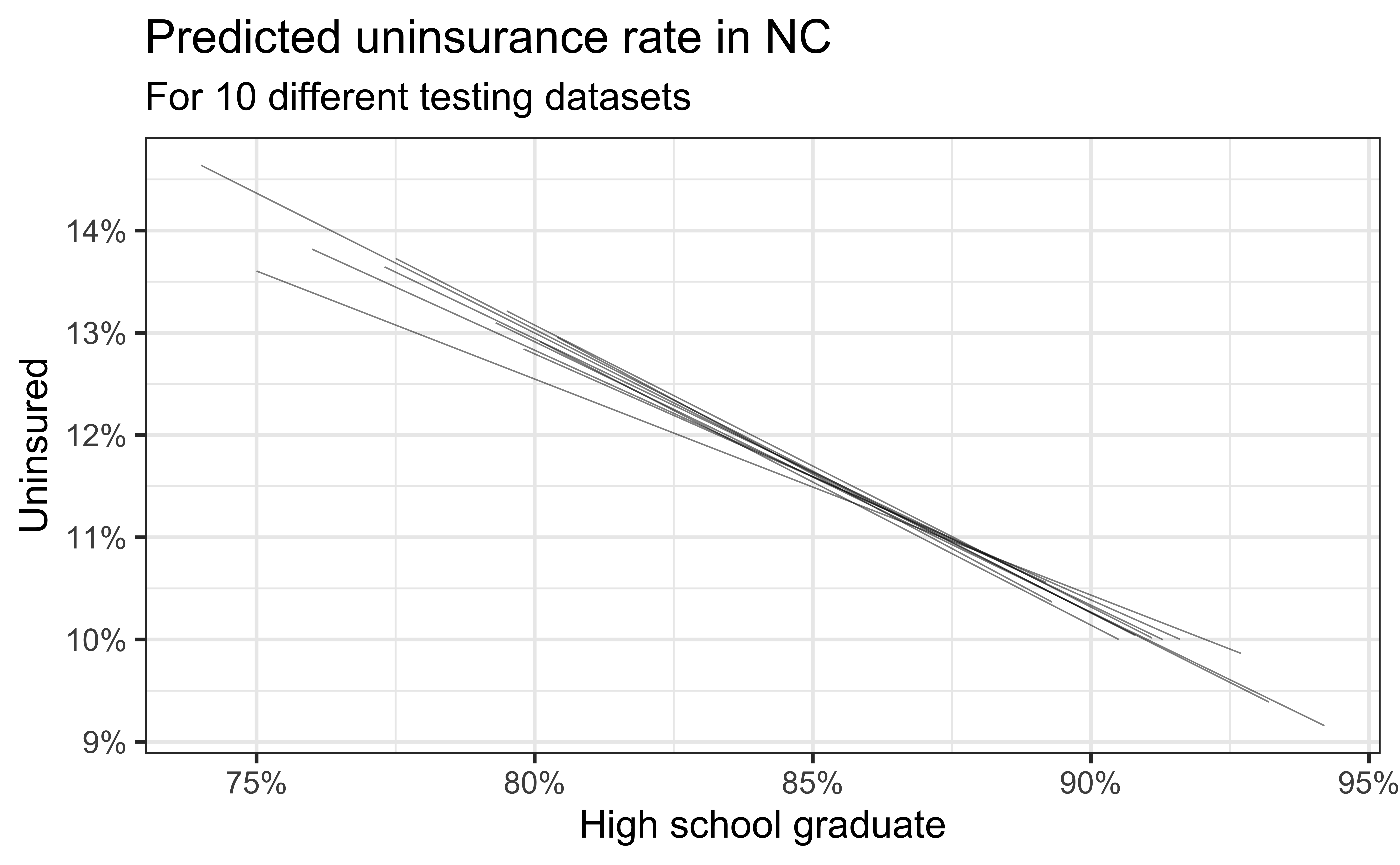
Predictive performance
- How consistent are the predictions for different testing datasets?
- How consistent are the predictions for counties with high school graduation rates in the middle of the plot vs. in the edges?
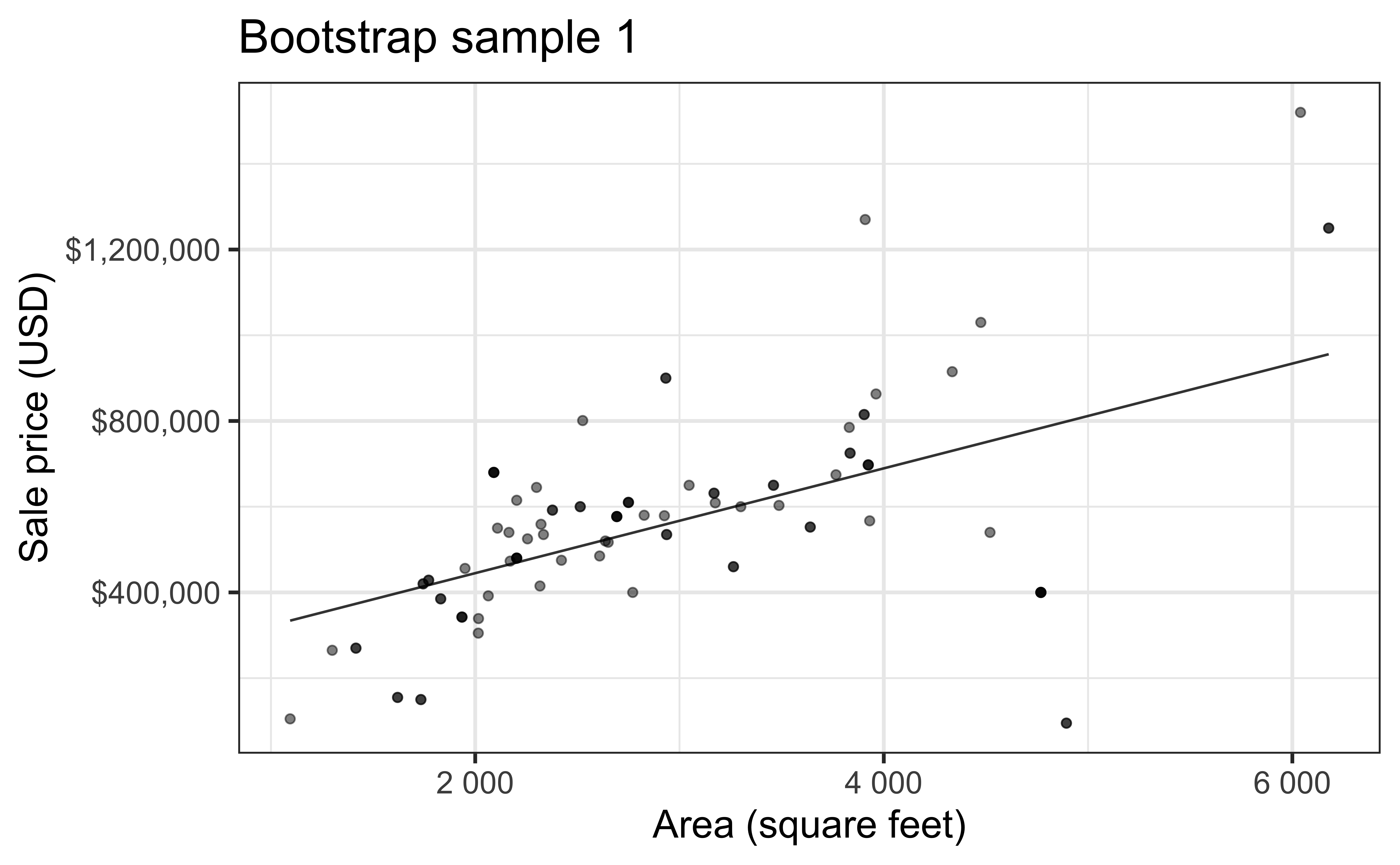
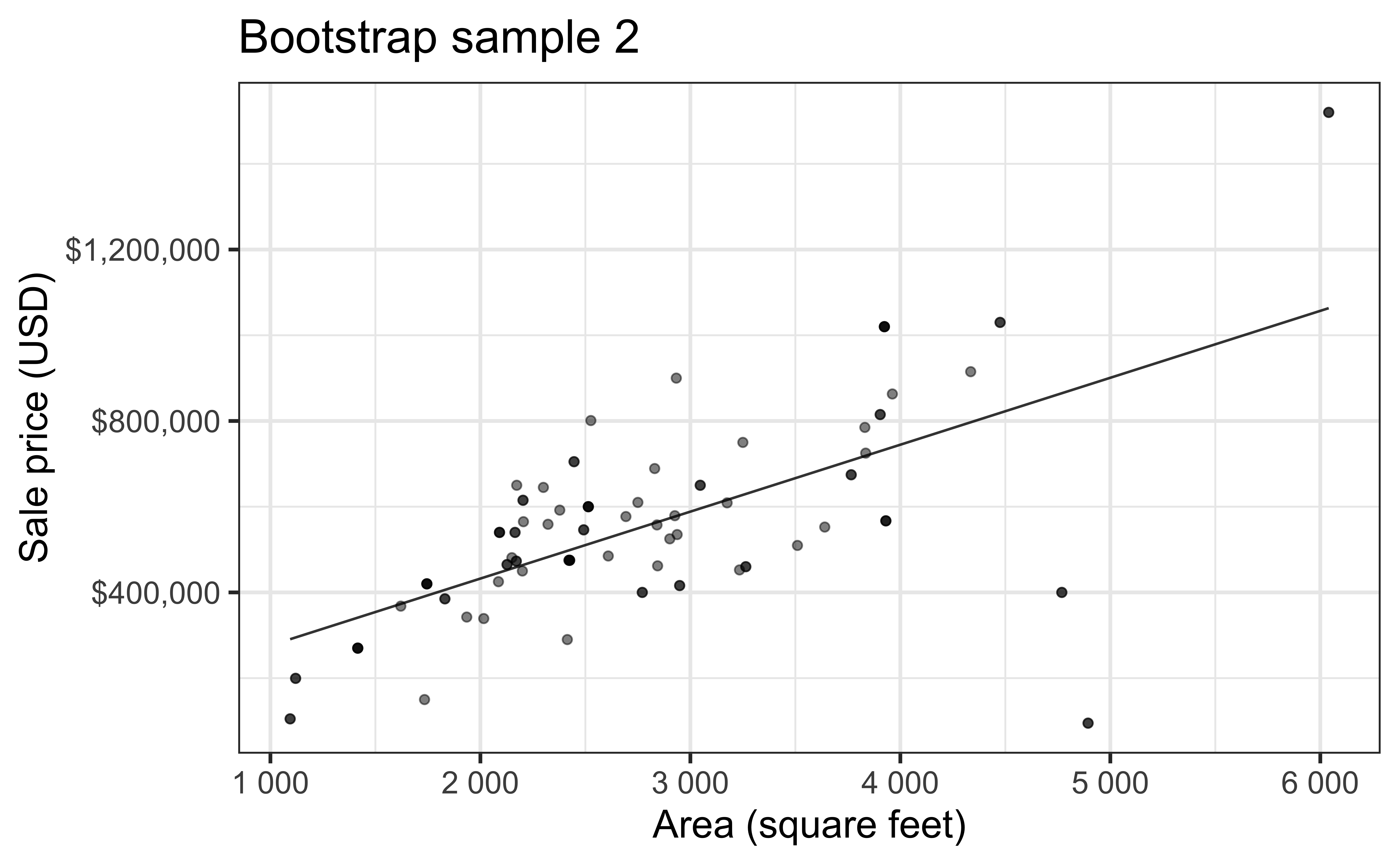
Simulation: bootstrapping
- Take a bootstrap sample – sample with replacement from the original data, same size as the original data
- Fit model to the sample and make predictions for that sample
- Repeat many times
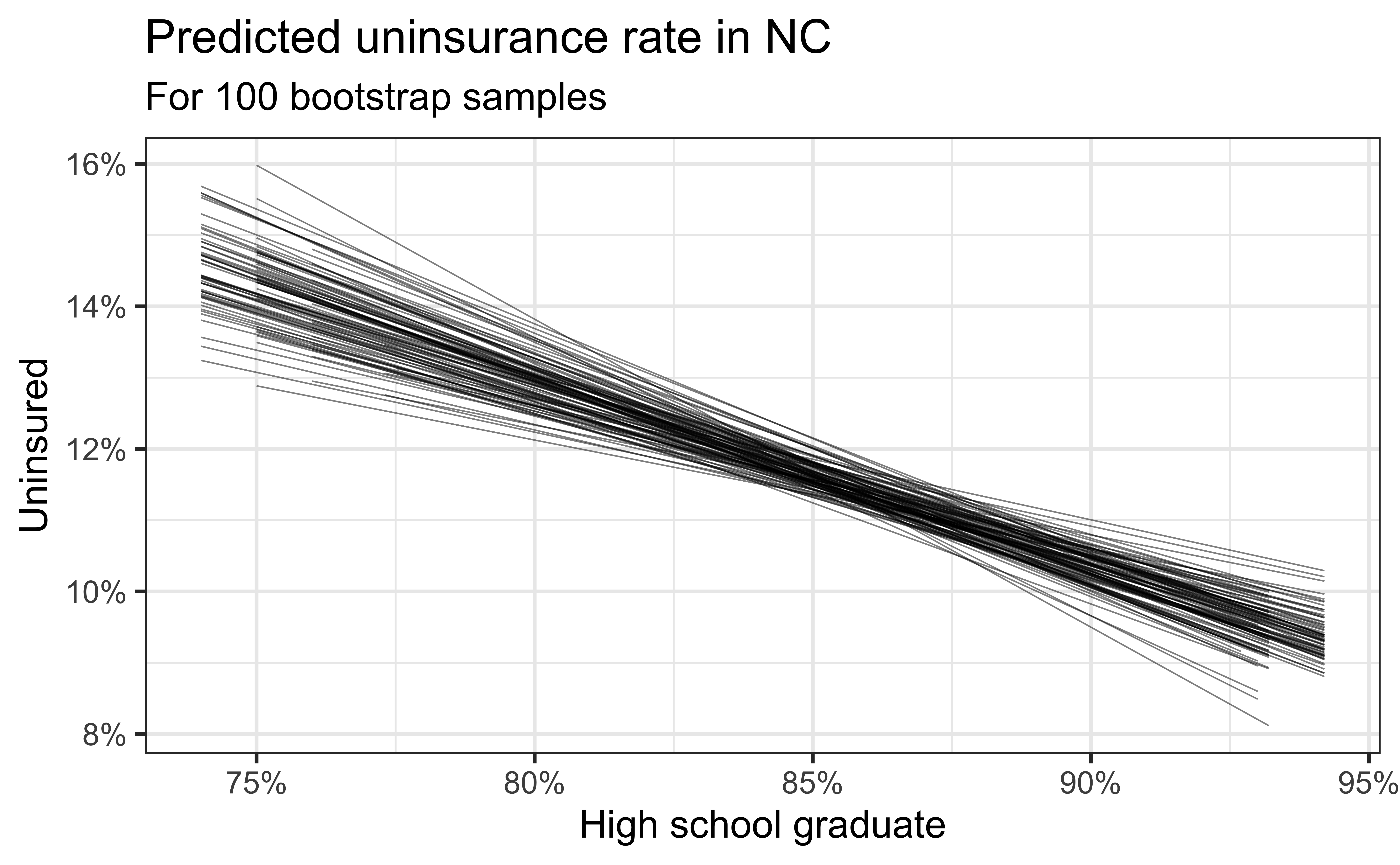
Predictive performance
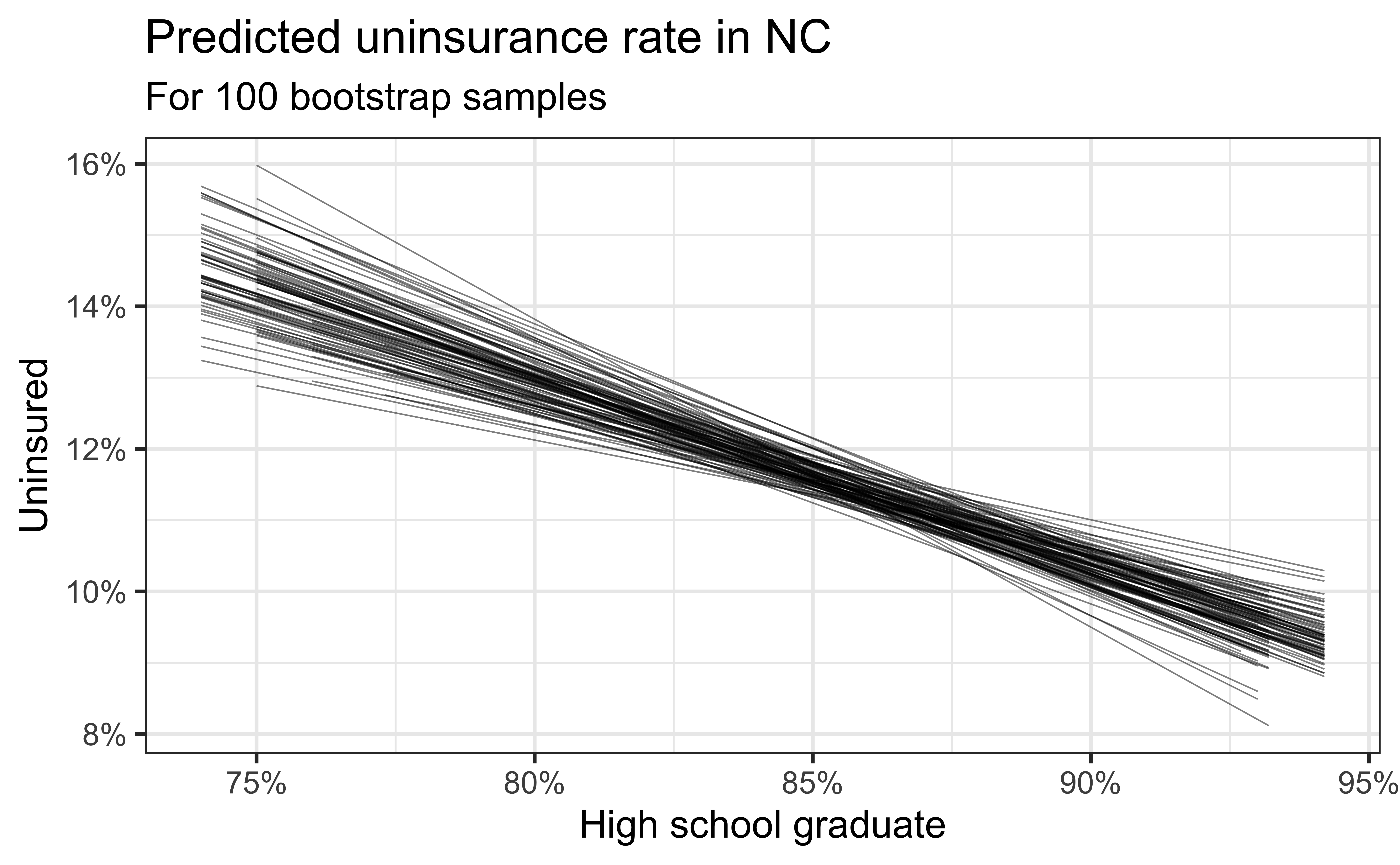
- How consistent are the predictions for different bootstrap datasets?
- How consistent are the predictions for counties with high school graduation rates in the middle of the plot vs. in the edges?
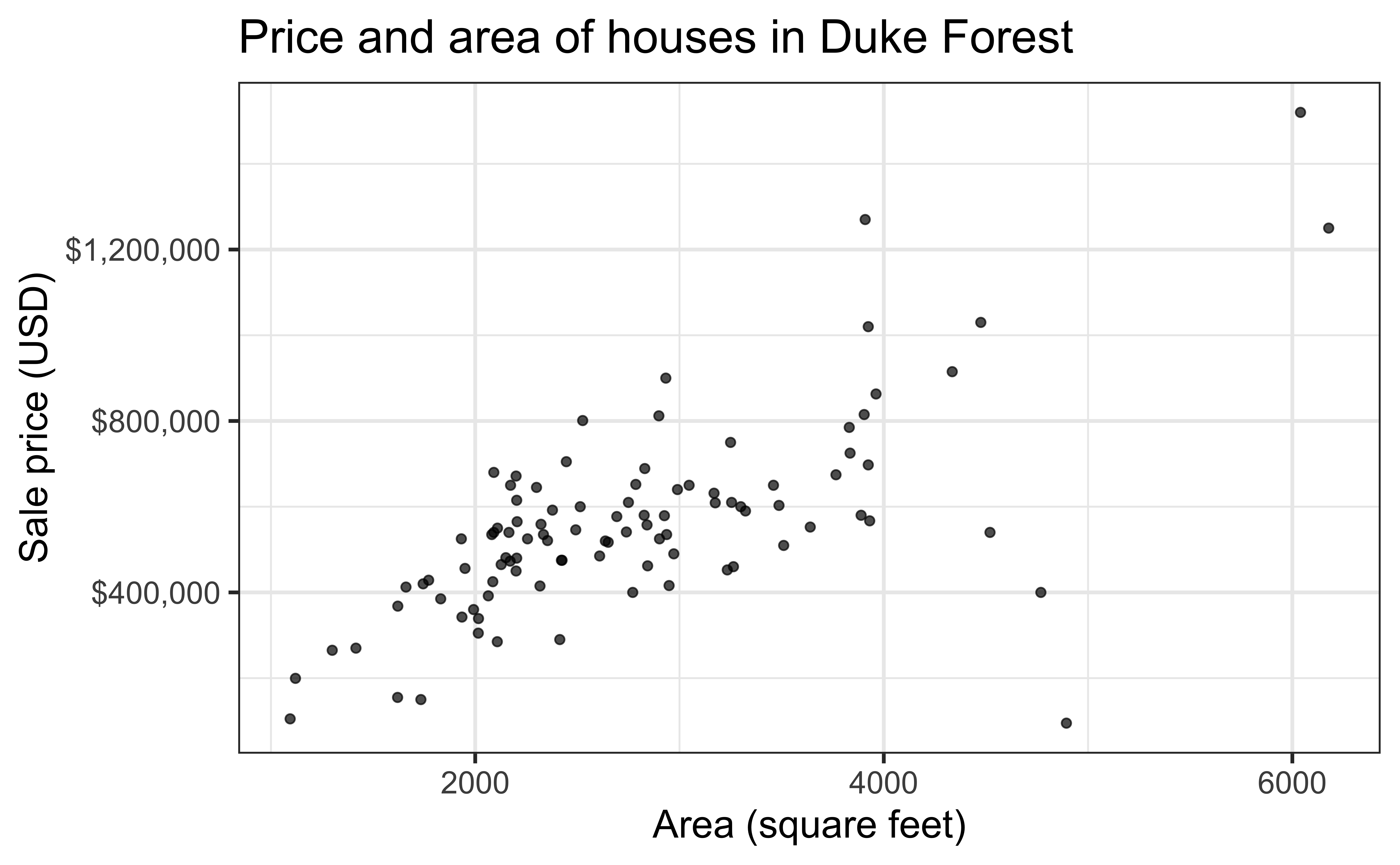
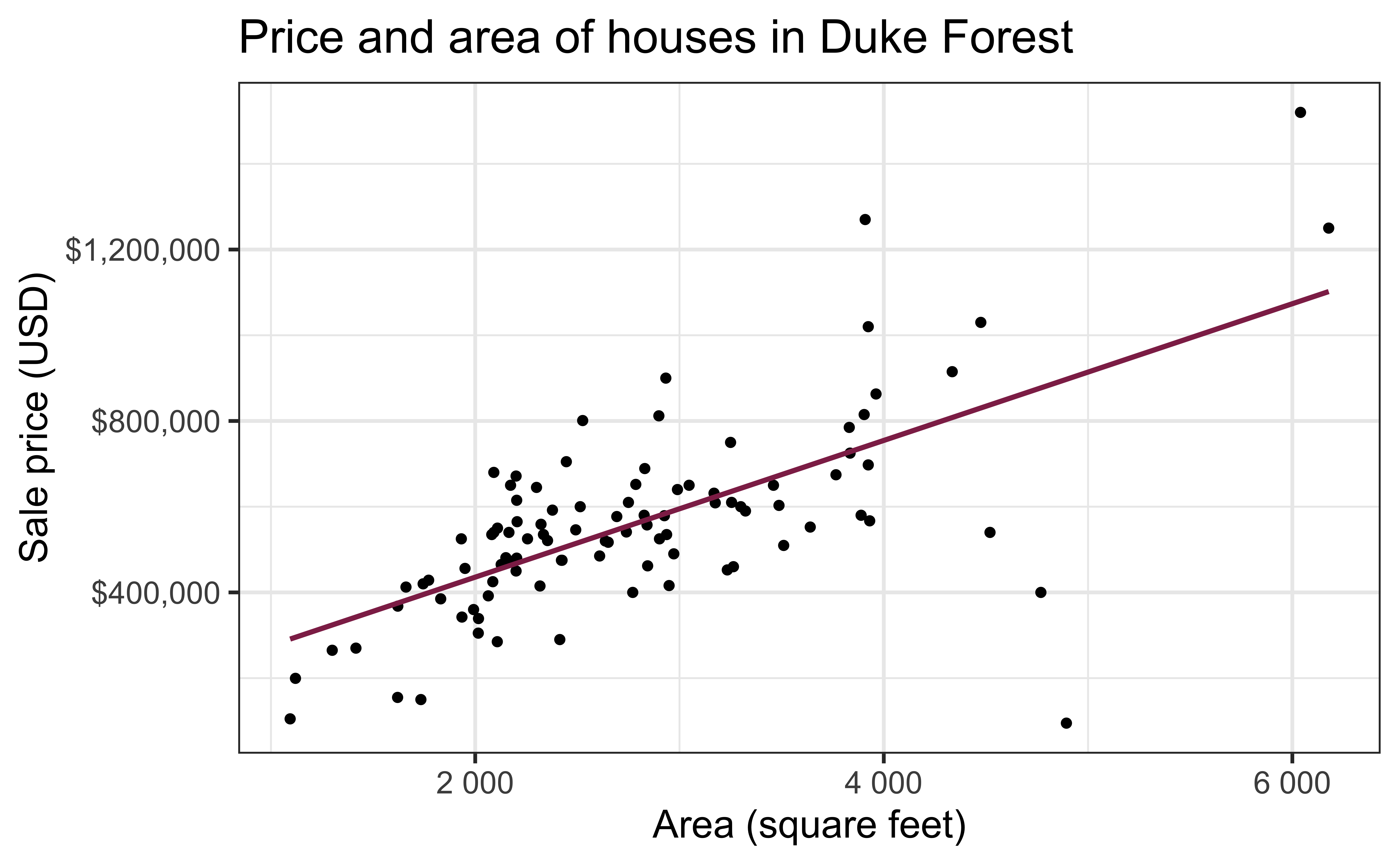
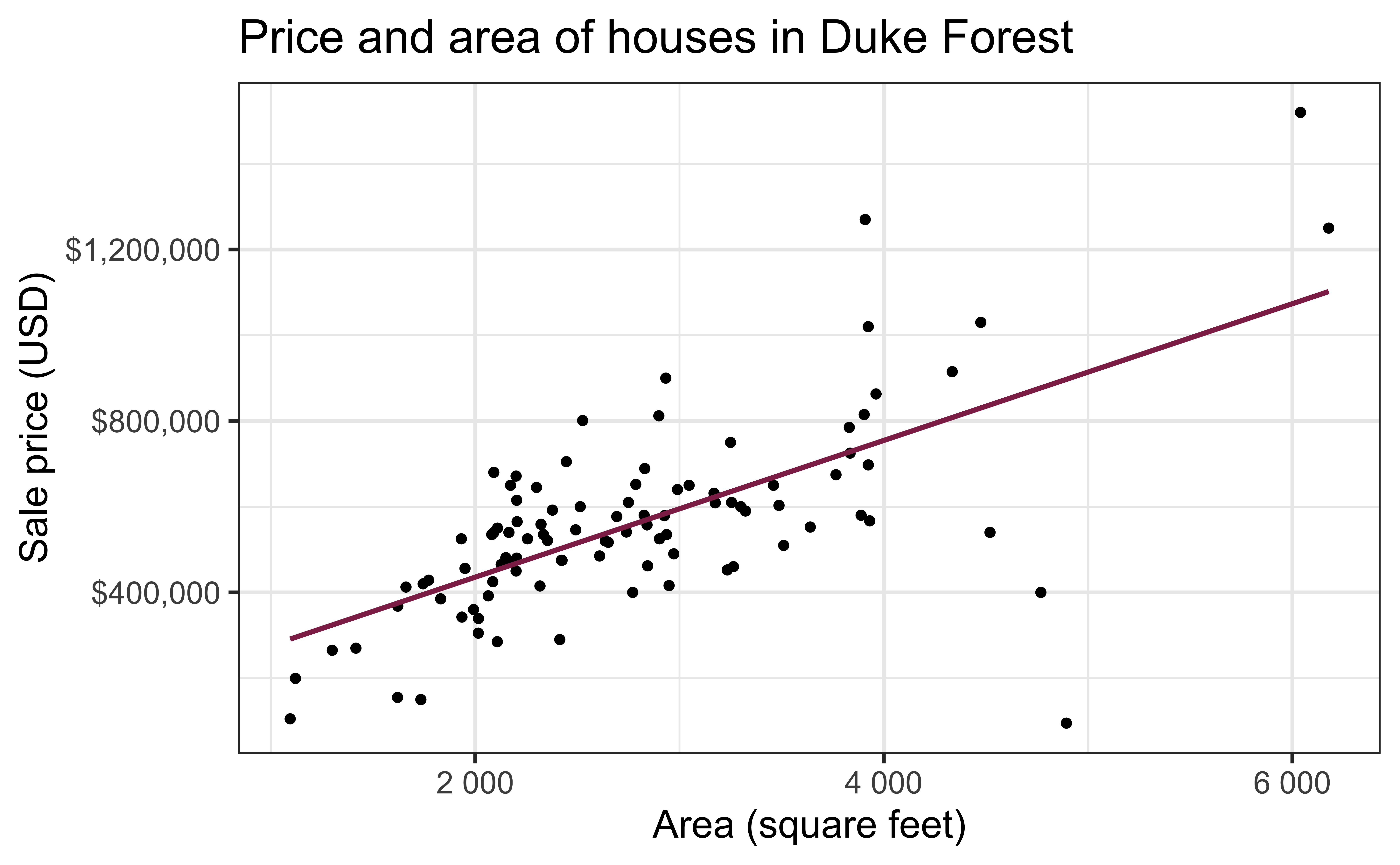
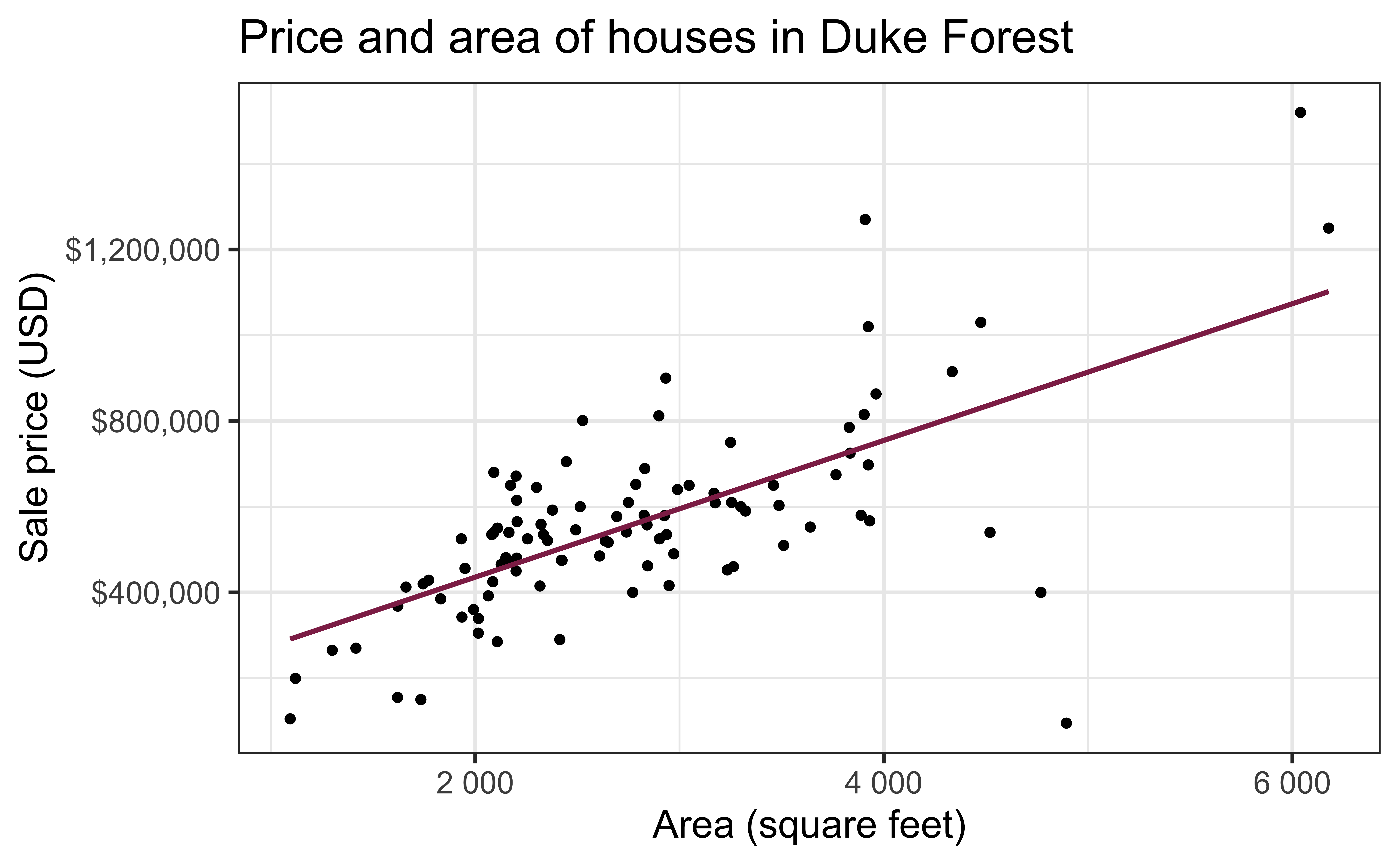
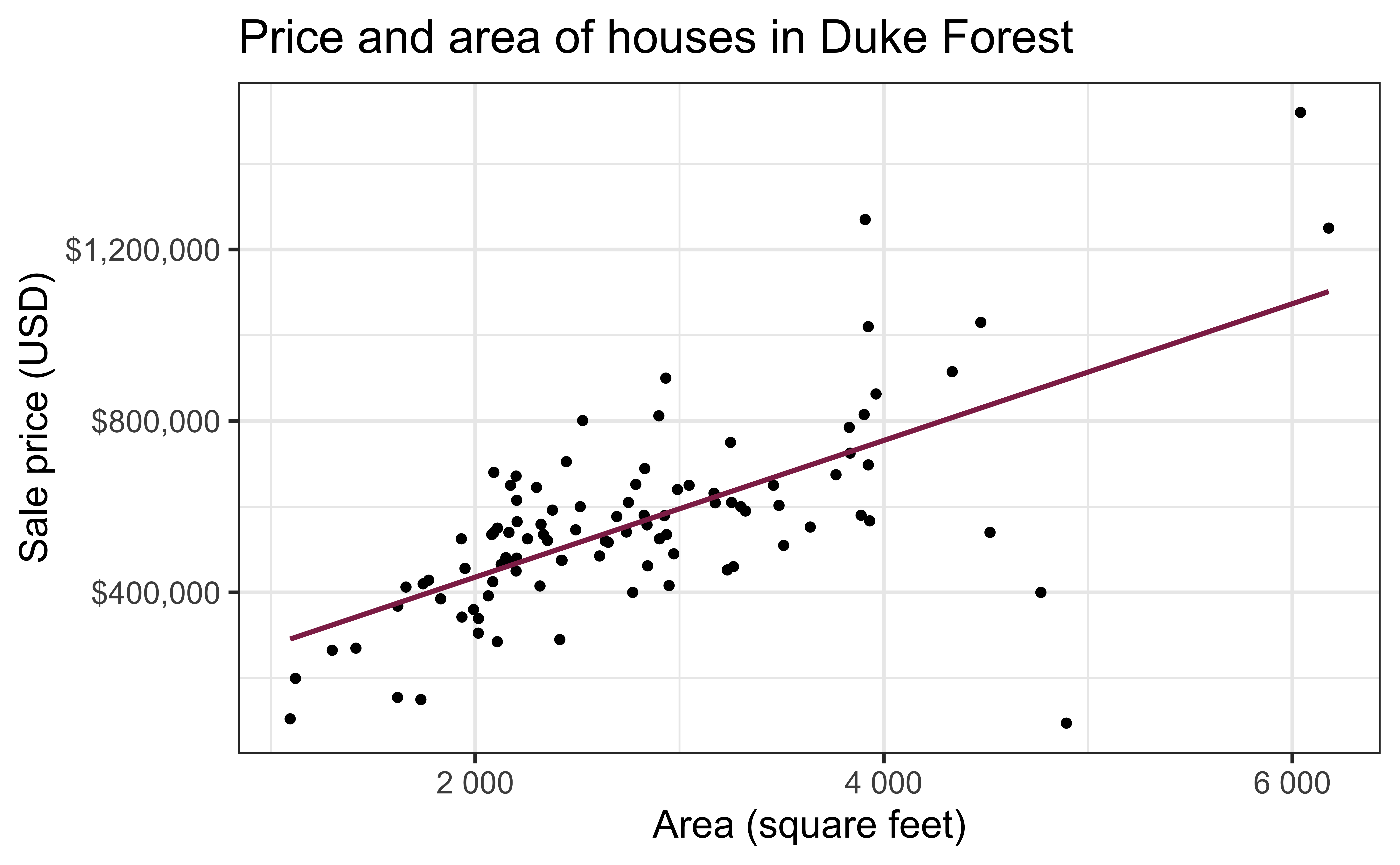
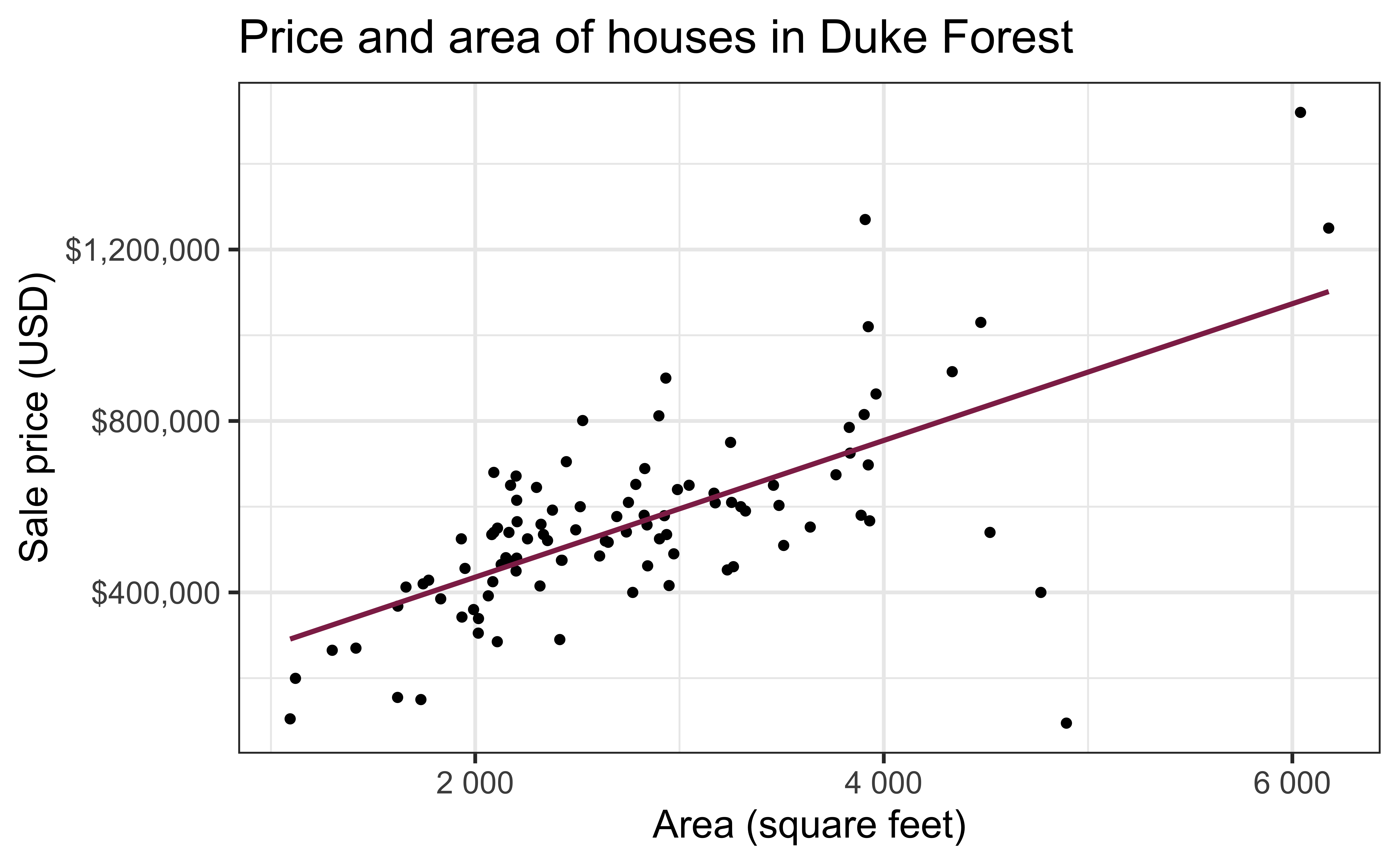
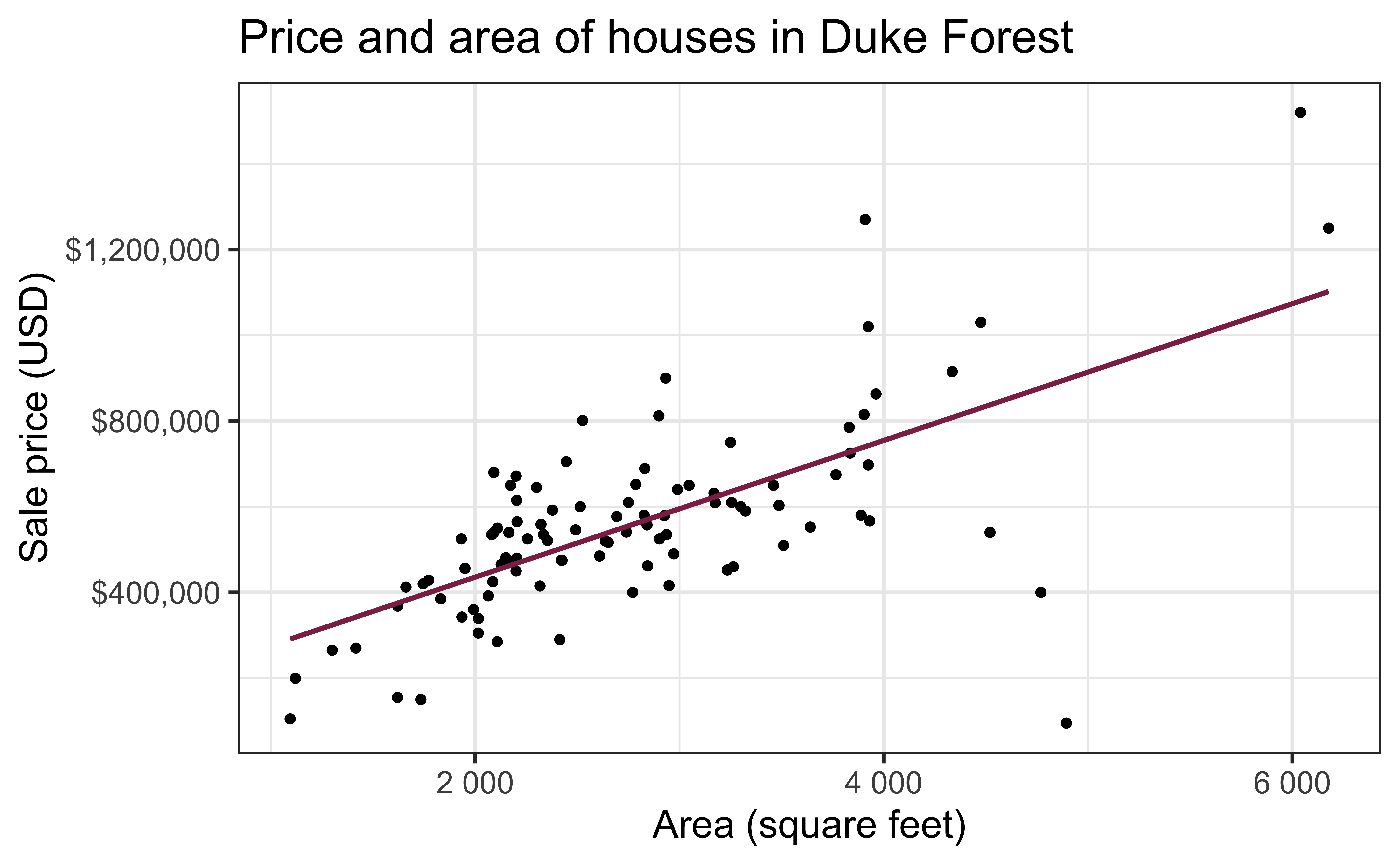
Data: Houses in Duke Forest
- Data on houses that were sold in the Duke Forest neighborhood of Durham, NC around November 2020
- Scraped from Zillow
- Source:
openintro::duke_forest

Goal: Use the area (in square feet) to understand variability in the price of houses in Duke Forest.
Exploratory data analysis
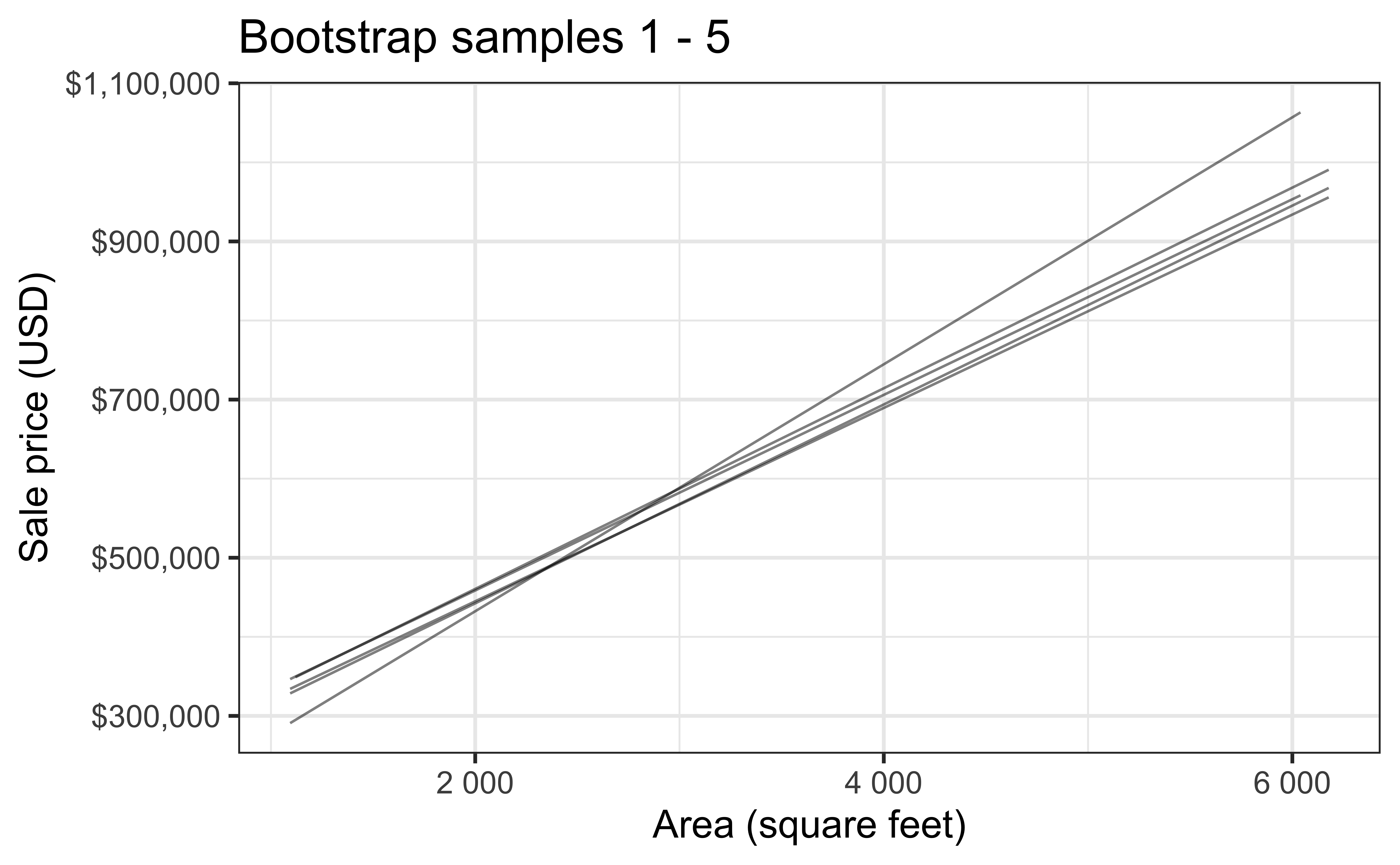
Bootstrap sample 1
Bootstrap sample 2
Bootstrap sample 3
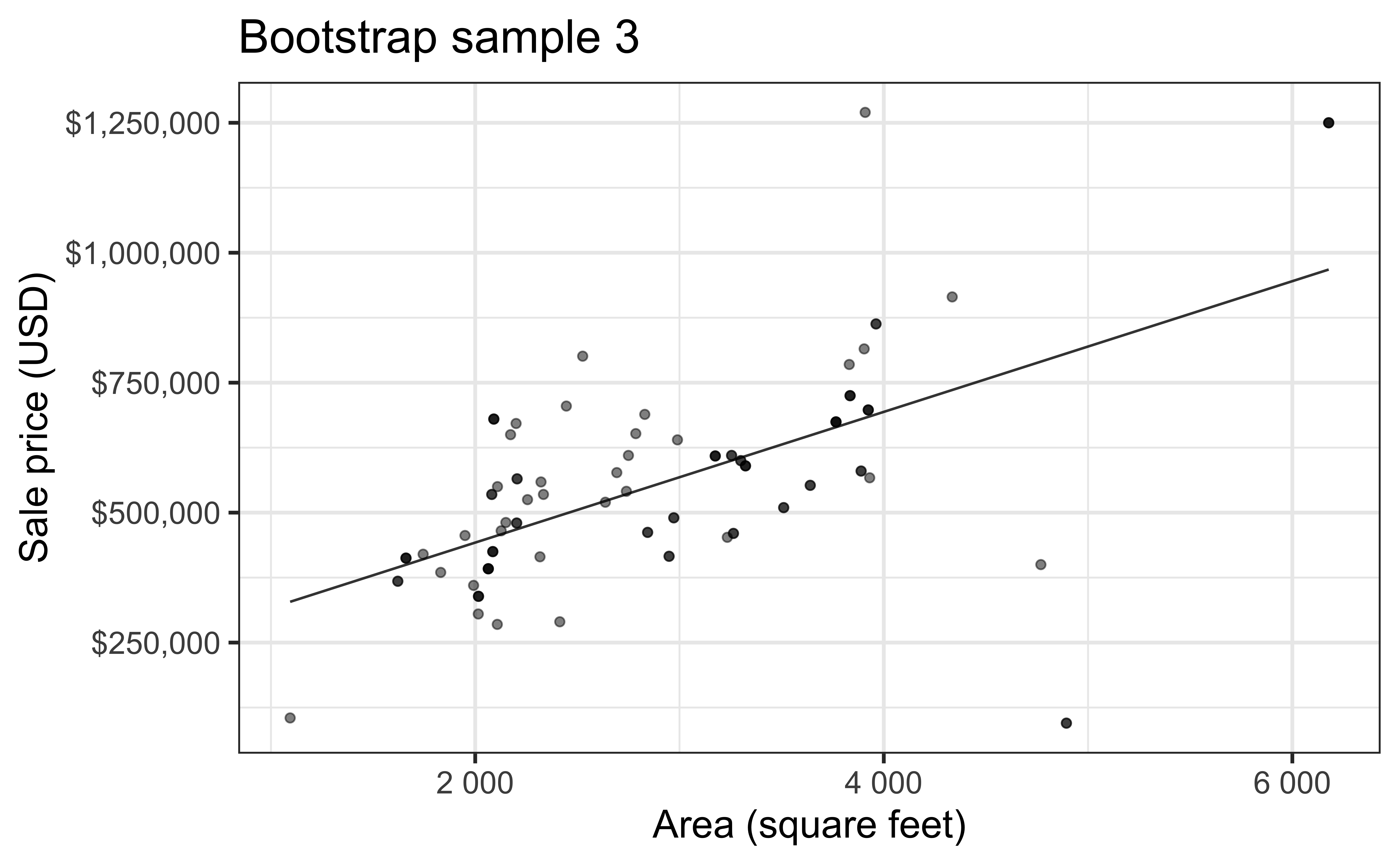
Bootstrap sample 4
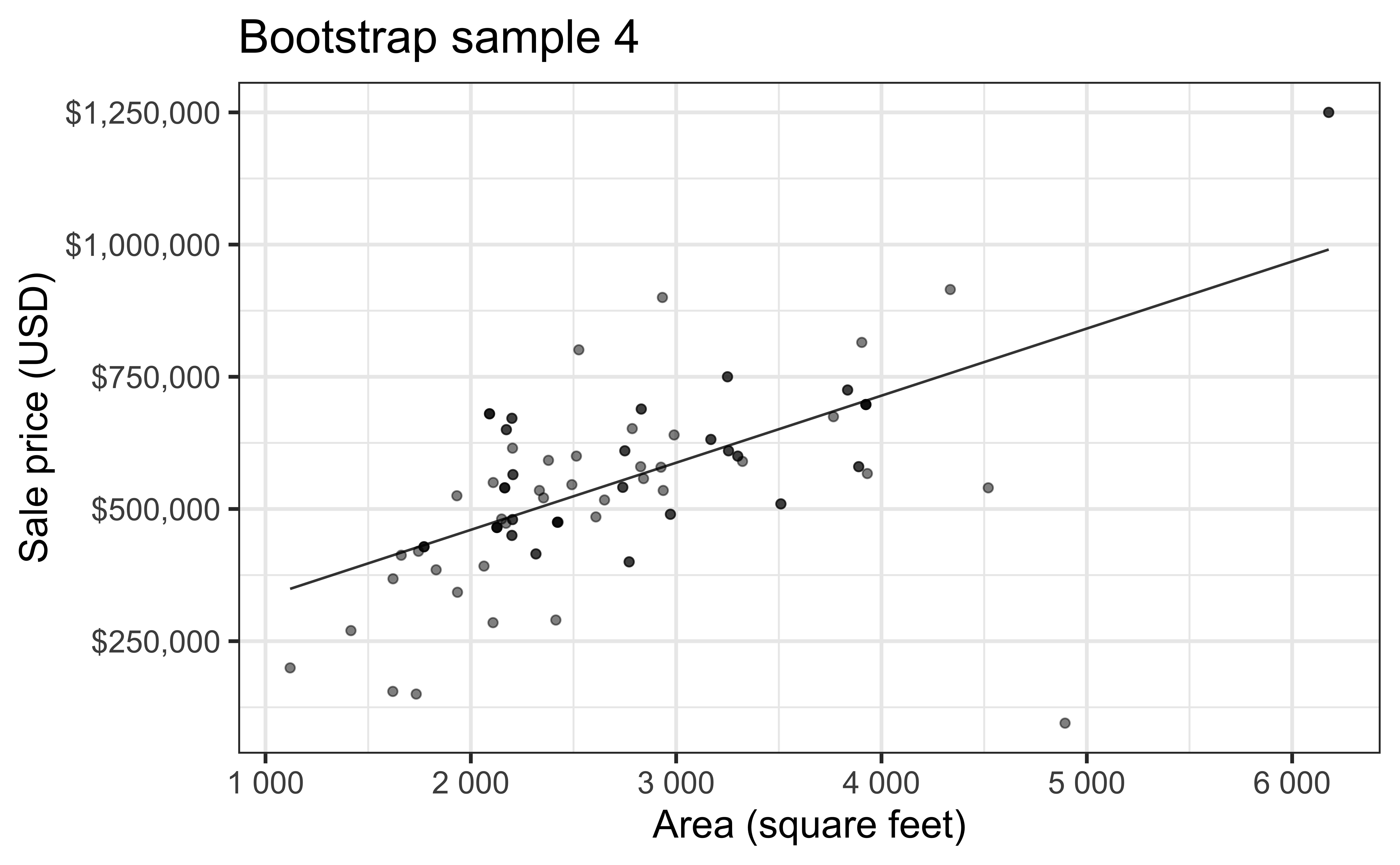
Bootstrap sample 5
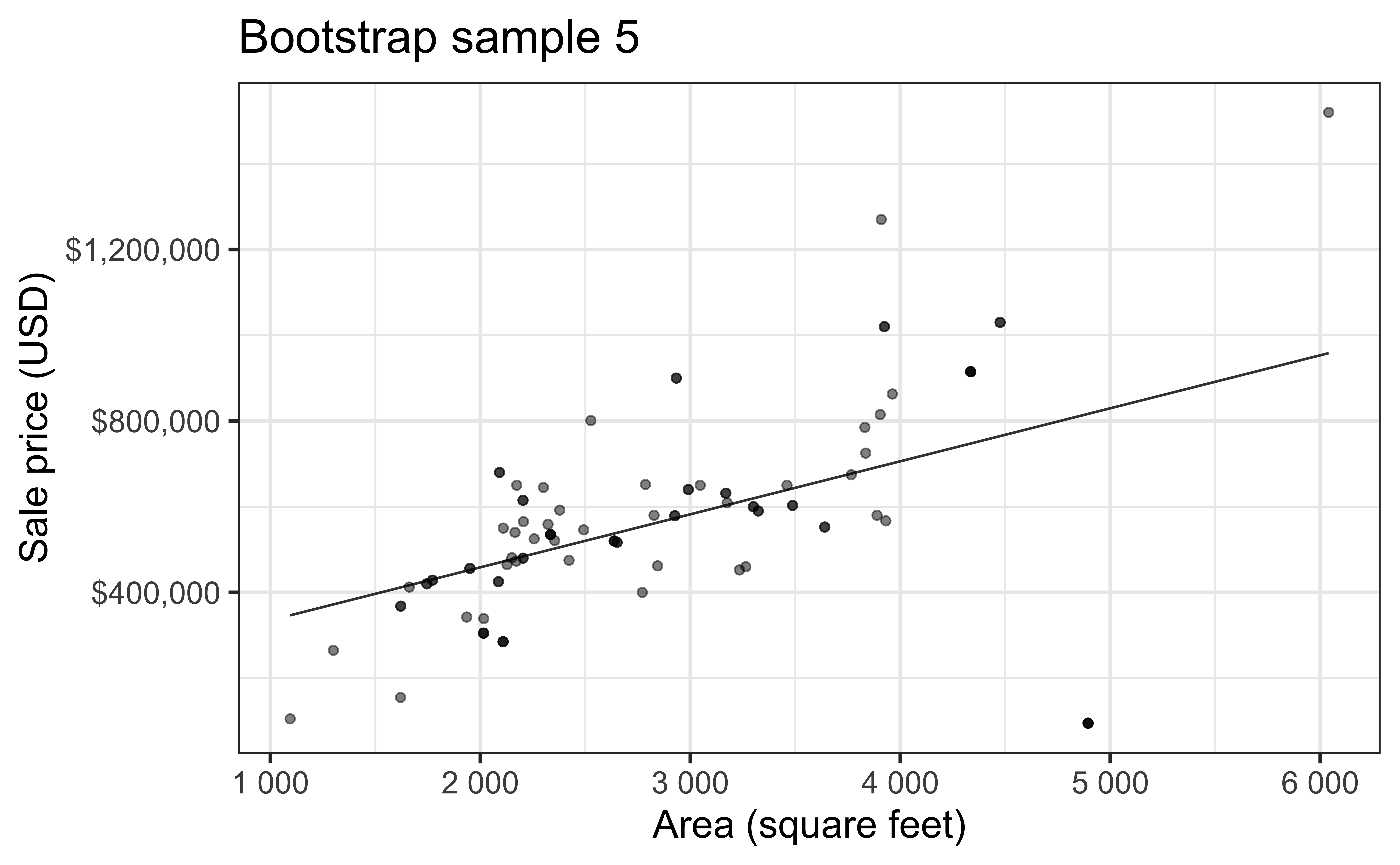
so on and so forth…
Bootstrap samples 1 - 5
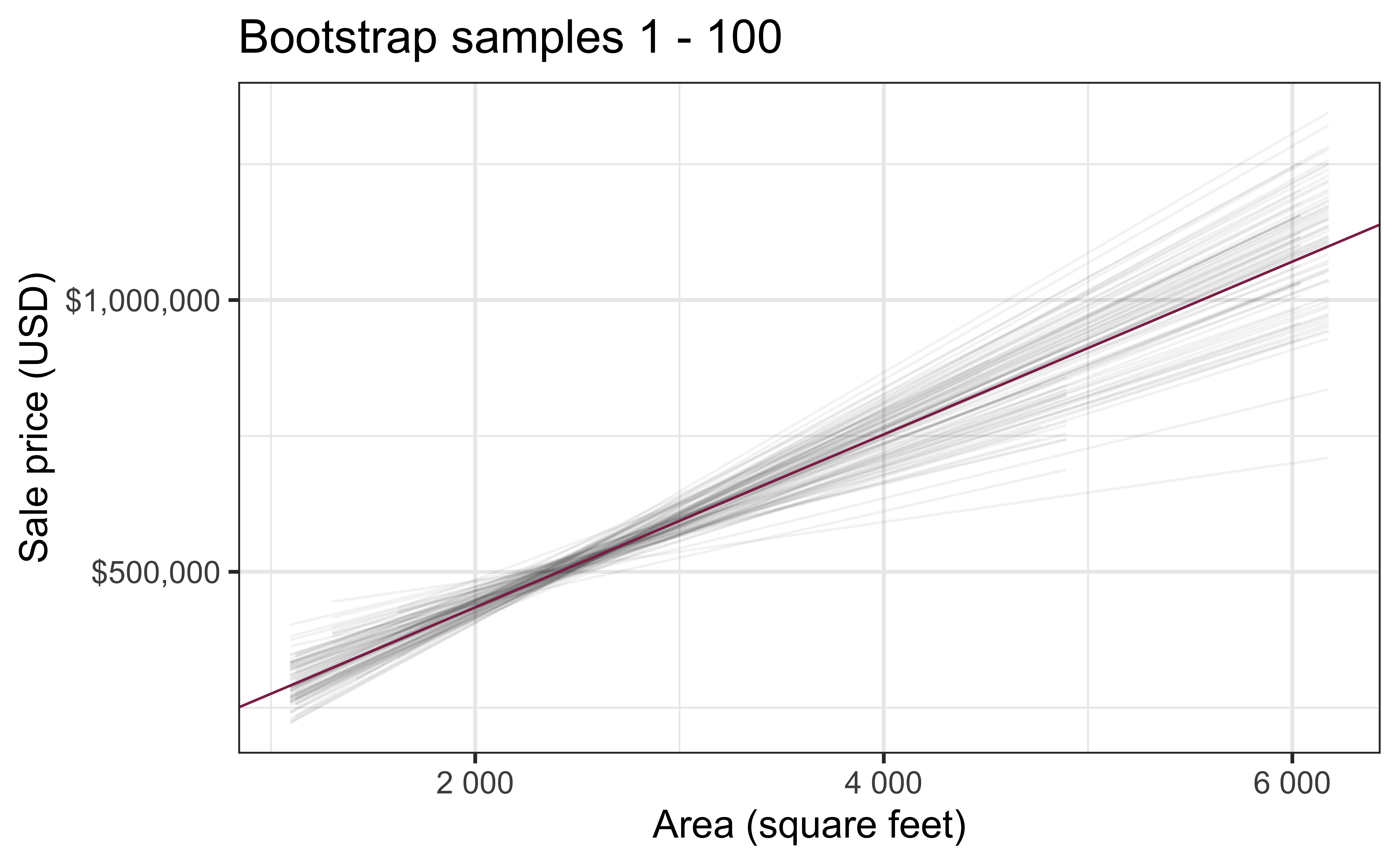
Bootstrap samples 1 - 100
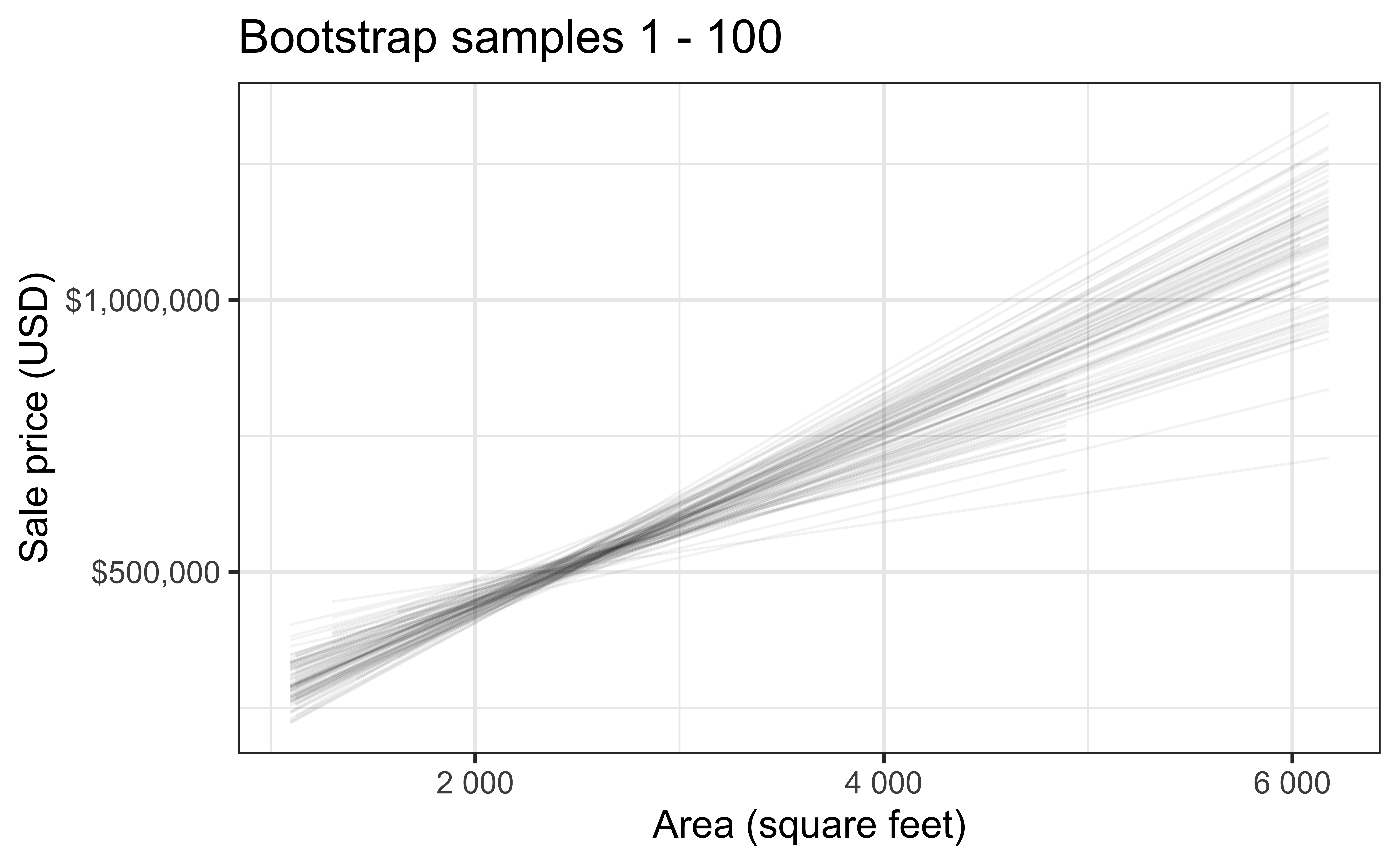
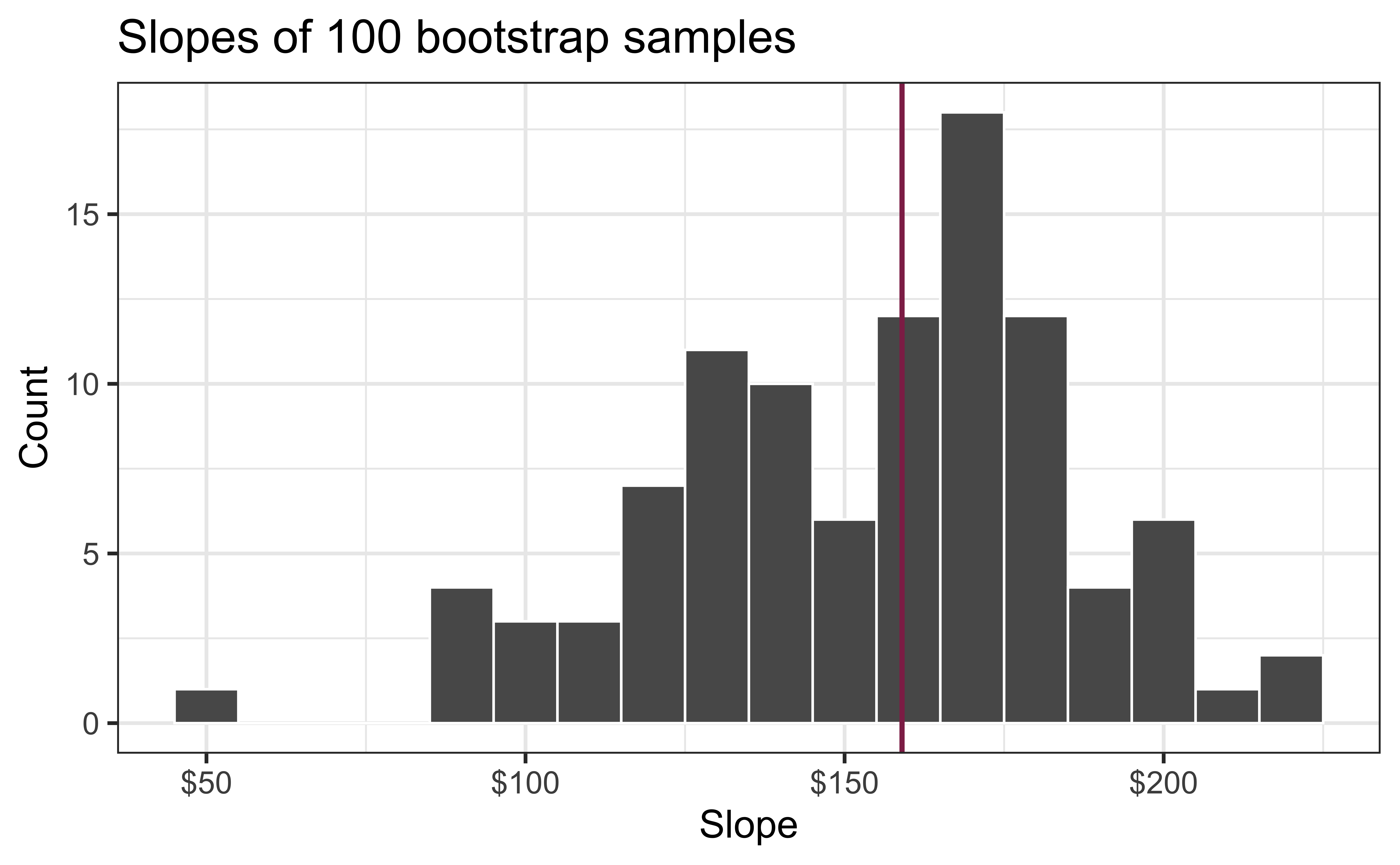
Slopes of bootstrap samples
Fill in the blank: For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $159, plus or minus ___ dollars.
Slopes of bootstrap samples
Fill in the blank: For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $159, plus or minus ___ dollars.
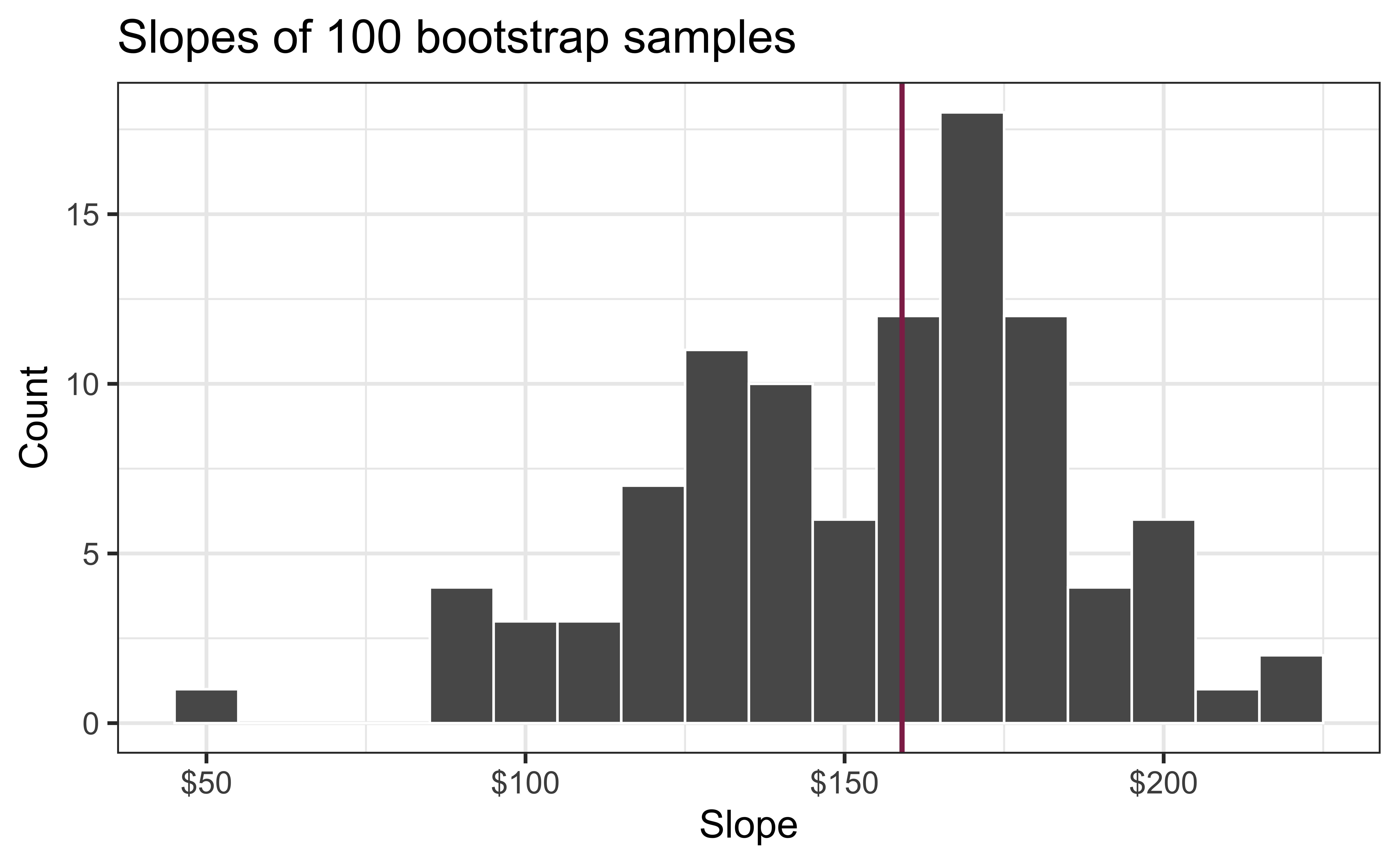
Confidence level
How confident are you that the true slope is between $0 and $250? How about $150 and $170? How about $90 and $210?
95% confidence interval
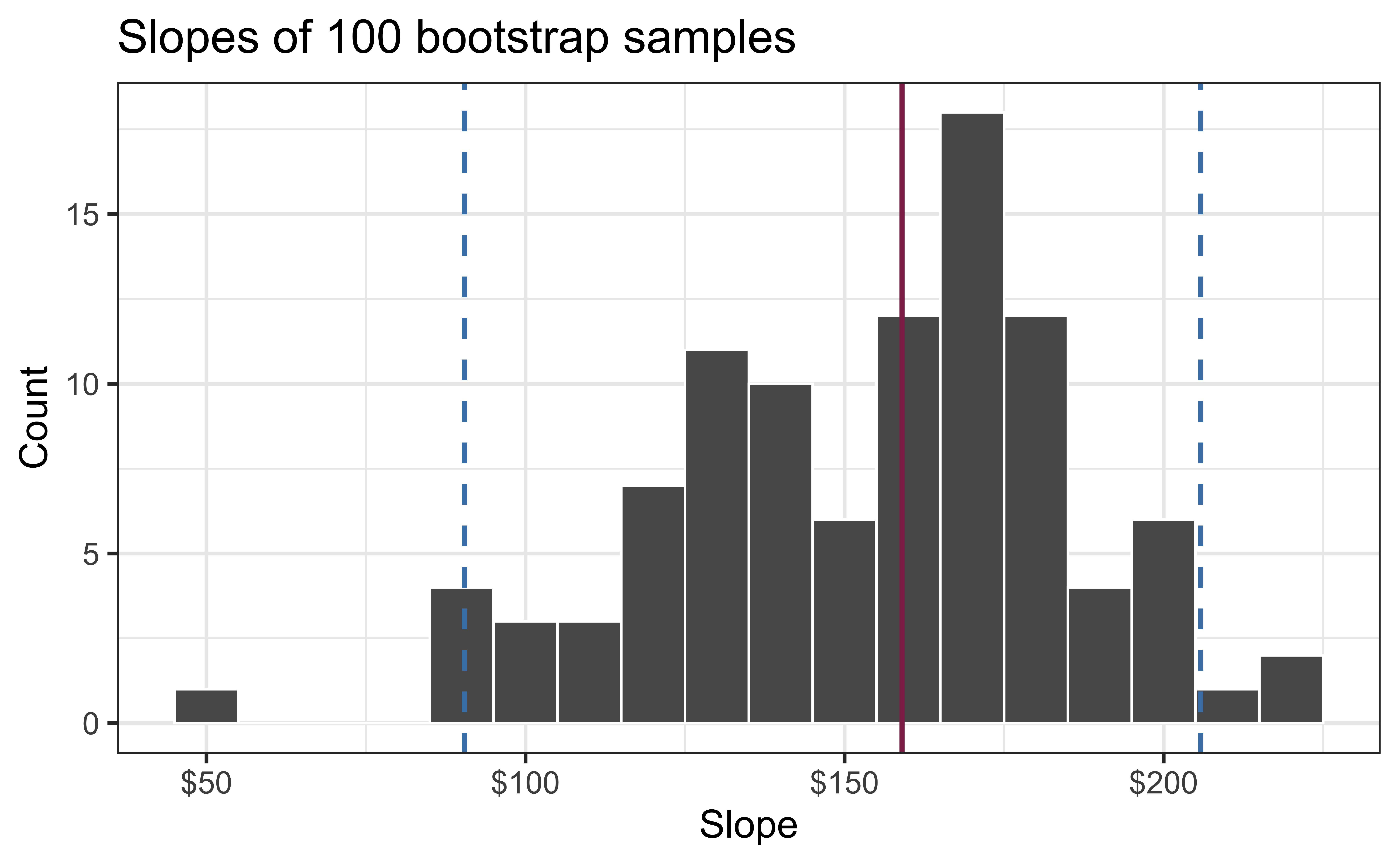
- A 95% confidence interval is bounded by the middle 95% of the bootstrap distribution
- We are 95% confident that for each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $90.43 to $205.77.
Precision vs. accuracy
If we want to be very certain that we capture the population parameter, should we use a wider or a narrower interval? What drawbacks are associated with using a wider interval?

Recap
Population: Complete set of observations of whatever we are studying, e.g., people, tweets, photographs, etc. (population size = \(N\))
Sample: Subset of the population, ideally random and representative (sample size = \(n\))
Sample statistic \(\ne\) population parameter, but if the sample is good, it can be a good estimate
Statistical inference: Discipline that concerns itself with the development of procedures, methods, and theorems that allow us to extract meaning and information from data that has been generated by stochastic (random) process
We report the estimate with a confidence interval, and the width of this interval depends on the variability of sample statistics from different samples from the population
Since we can’t continue sampling from the population, we bootstrap from the one sample we have to estimate sampling variability